

Kalman Filter và bài toán chuỗi thời gian
Nội dung bài viết
Kalman Filter là một mô hình Linear-Gaussian State Space Model thuộc nhóm thuật toán dự đoán chuỗi thời gian. Thuật toán được lấy tên theo Rudolf E. Kálmán, một nhà khoa học ảnh hưởng quan trọng trong quá trình phát triển thuật toán.

Nếu là một kỹ sư điều khiển hệ thống, bạn hiểu rằng điều khiển hệ thống không đơn thuần nghĩa là đo rồi điều khiển những gì mình đo được. Đo lường chính xác nhường nào, hệ thống điều khiển càng hoạt động ổn định nhường nấy.
Hãy quay ngược thời gian về những năm 1960 với những khó khăn của những kỹ sư thiết kế phi thuyền Apollo trong xử lý tín hiệu. Dữ liệu thô đo được từ máy tính, được đo từ các cảm biến như con quay hồi chuyển, gia tốc kế, dữ liệu rađa vốn dĩ đầy nhiễu, đầy lỗi ngẫu nhiên và đặc biệt lộn xộn không chính xác. Khi lao về mặt trăng ở tốc độ cao, ai mà chắc chắn rằng điều gì sẽ xảy ra với những gì bạn điều khiển, bạn sẽ không muốn Apollo lao thẳng vào nhà mình đâu!
Kalman Filter là một công cụ mạnh mẽ kết hợp thông tin không chắc chắn ở thời điểm hiện tại cùng với thông tin đầy nhiễu loạn của môi trường sang một dạng thông tin mới đáng tin cậy hơn để phục vụ dự đoán tương lai. Điểm mạnh của Kalman Filter là chạy rất nhanh và tính ổn định cao.
Một trong những ứng dụng đầu tiên của Kalman Filter là được áp dụng vào phi thuyền Apollo:
The Apollo computer used 2k of magnetic core RAM and 36k wire rope […]. Clock speed was under 100 kHz […]. The fact that the MIT engineers were able to pack such good software (one of the very first applications of the Kalman filter) into such a tiny computer is truly remarkable.
— Phỏng vấn Jack Crenshaw bởi Matthew Reed, TRS-80.org (2009)
1. Ý tưởng cơ bản thuật toán
Thuật toán có rất nhiều ứng dụng vào các bài toán khác nhau. Tuy nhiên để dể hình dung, bây giờ chúng ta hãy tưởng tượng mình là một nhà sáng chế phi thuyền Thetalo (một phiên bản lỗi từ Apollo).
Phi thuyền sẽ gửi về thông tin trạng thái sau mỗi khoảng thời gian nhất định thông qua bộ cảm biến, nhiệm vụ của chúng ta là dự đoán trạng thái trên phi thuyền để phục vụ tác vụ điều khiển hệ thống.
Gọi là trạng thái vị trí và vận tốc hiện tại của phi thuyền. Tại mỗi thời điểm , bạn không hề có thông tin chính xác về .
Vì sao vậy? Hệ mà chúng ta điều khiển không nằm trong một môi trường lý tưởng, nhiều tác động từ môi trường xung quanh mà chúng ta không đoán trước ở sẽ ảnh hưởng những tính toán ban đầu.
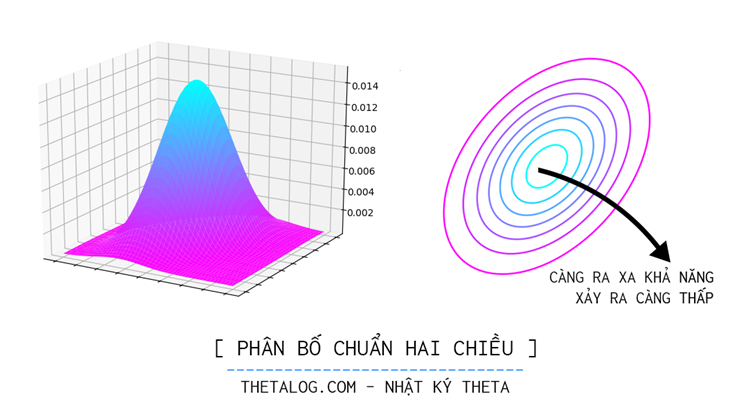
Biết đâu được một cơn gió vô tình, một cơn mưa ngang qua, một trận sấm sét cuồng phong sẽ làm mọi tính toán sai lầm. Trực cảm cho ta thấy nó đang ở đâu đó trong không gian này, tại một số vùng nào đó khả năng xảy ra cao hơn, tại một số vùng nào đó khả năng xảy ra thấp hơn. Phân bố xác suất như một bản đồ về sự chắc chắn, một niềm tin về những sự kiện xảy ra.
Lựa chọn phân bố xác suất phù hợp là điều cần thiết như thể lựa chọn cho mình một niềm tin, trong mô hình Kalman Filter phân bố xác suất được chọn là phân bố chuẩn nhiều chiều. Sở dĩ chọn phân bố chuẩn nhiều chiều là vì đây là phân bố liên tục phù hợp bài toán đang xét, một vài tính chất đặc biệt của phân bố chuẩn nhiều chiều thuận lợi cho tác vụ ước lượng tham số.
Tại mỗi thời điểm , giả định vector ngẫu nhiên có phân bố chuẩn nhiều chiều hay với là kỳ vọng của , là ma trận hiệp phương sai với mỗi phần tử tại hàng cột thể hiện độ biến thiên cùng nhau của hai biến ngẫu nhiên thứ và . Công thức tổng quát của hàm mật độ xác suất vector ngẫu nhiên với kỳ vọng , ma trận hiệp phương sai với số chiều (trong ví dụ đang xét, ) là:
Lập luận theo cách trên lại có một ưu thế nữa, trong nhiều bài toán khoa học kỹ thuật, đôi lúc bạn cần biết xác suất xảy ra trong một vùng nào đấy, chẳng hạn:
- Đôi lúc chúng ta chỉ quan tâm đến một vùng nào đó của một đại lượng, chẳng hạn từ đến độ C thì CPU máy tính phải tắt vì nhiệt độ vượt ngưỡng an toàn, xác suất để nhiệt độ rơi vào vùng này là bao nhiêu nhỉ? Tương tự với một tập đại lượng, chúng ta quan tâm đến một vùng giá trị nào đó thật sự quan trọng trong bài toán đang xét.
- Với hàm mật độ xác suất liên tục chúng ta có thể dể dàng tính xác suất xảy ra trong vùng bằng tích phân , thật tiện lợi đúng không nào!
Giả định rằng tại thời điểm phi thuyền có:
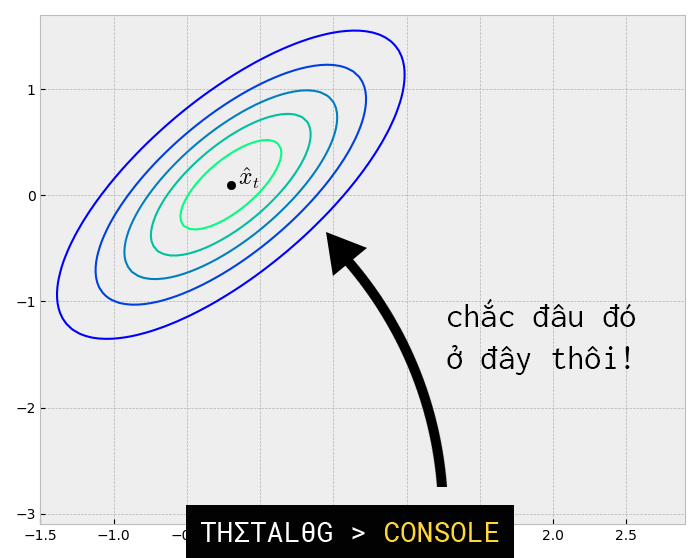
Thông tin mà chúng ta có không chỉ có những gì chúng ta tiên lượng về nó (cách chúng ta đoán về ). Trên phi thuyền được gắn một cảm biến đặc biệt cho phép đo trạng thái hiện tại và gửi thông tin về trụ sở.
Tuy nhiên, mặc dù vậy, cảm biến này lại không chính xác, bộ cảm biến cho chúng ta biết trạng thái hiện tại là
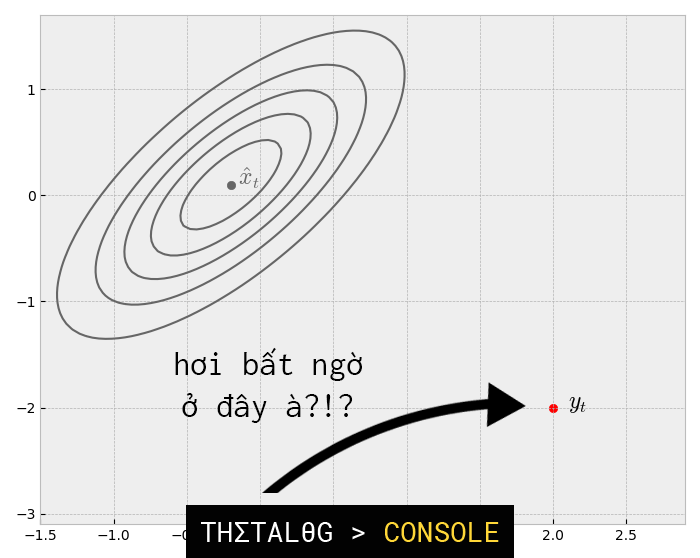
Trong trường hợp này, chúng ta giả định rằng: với là một vector ngẫu nhiên nhiễu có phân bố chuẩn nhiều chiều , chúng ta gọi là nhiễu mô hình quan sát (observation noise).
Giả định trên có thể hiểu được xem như là “nhiễu quan sát được từ “, là kết quả của tổ hợp tuyến tính từng thành phần dựa trên ma trận và bị ảnh hưởng cộng thêm một lượng nhiễu môi trường với vector ngẫu nhiên . Người ta gọi công thức trên là mô hình quan sát, nó thể hiện quá trình biến đổi thành đồng thời bị ảnh hưởng nhiễu từ môi trường.
Giờ đây, chúng ta có niềm tin của chúng ta về trạng thái phi thuyền qua hàm mật độ xác suất và một sự kiện đã xảy ra là thông tin thu được từ bộ cảm biến - trạng thái , liệu rằng chúng ta có thể kết hợp cả hai thông tin đang có thành một thông tin mới có ý nghĩa hơn, giúp chúng ta hiểu hơn về trạng thái hiện tại hệ thống hay không?
Biết sẽ giúp chúng ta cập nhật niềm tin về như thế nào? Nếu bạn đang tìm một giải pháp như trên, có lẽ định lý Bayes là một câu trả lời chúng ta đang tìm:
- hàm mật độ xác suất tiên nghiệm, niềm tin của chúng ta không phụ thuộc vào sự kiện xảy ra.
- hàm mật độ xác suất khả dĩ, mật độ xác suất có điều kiện khi biết trạng thái xảy ra, vì chúng ta biết rằng là một vector ngẫu nhiên sao cho , khi biết xảy ra nghĩa là là một vector hằng, vector ngẫu nhiên được biểu diễn bằng một vector hằng cộng thêm một vector ngẫu nhiên có phân bố chuẩn nhiều chiều , hay nói cách khác hiện tại là một phân bố chuẩn nhiều chiều. Phân bố .
- hàm mật độ xác suất biên không phụ thuộc vào đóng vai trò như một hằng số chuẩn hóa.
Phân bố được tìm như thế nào? Trên nền tảng Linear Gaussian Systems (LGS - mô hình phân bố chuẩn tuyến tính), lời giải của định lý Bayes cho bài toán này như sau:
| Định lý Bayes cho Linear Gaussian Systems |
|---|
|
Giả định có hai vector ngẫu nhiên và với là vectơ ẩn, là vector nhiễu quan sát được từ với:
|
Tuy nhiên nếu tính toán trực tiếp ma trận hiệp phương sai như trên thì có lẽ bạn vừa bỏ qua một vài “điều thú vị” trong đại số tuyến tính khiến giải pháp của chúng ta thú vị hơn!
| Đồng nhất thức ma trận Woodbury (hay còn gọi matrix inversion lemma) |
|---|
|
Cho ma trận , , , Đồng nhất thức Woodbury nói rằng: Nghĩa là khi bạn có nhu cầu tính toán công thức bên trái, bạn có thể xử dụng công thức bên phải để thay thế! Nó có lợi điểm gì trong bài toán này nhỉ? TL;DR: phần chứng minh này bạn có thể xem thêm tài liệu [8]. |
Trước khi giải thích ý nghĩa của đồng nhất thức ma trận Woodbury trong Kalman Filter, chúng ta hãy cùng nhau viết lại lời giải phân bố hậu nghiệm vừa tìm được, chúng ta gọi đây là “phân bố lọc” (Filtering Distribution):
Với tham số kỳ vọng và ma trận hiệp phương sai của phân bố chuẩn nhiều chiều:
Ý nghĩa của đồng nhất thức ma trận Woodbury: Trong nhiều ứng dụng theo thời gian thực, thường thì chỉ có một số ít trạng bạn nhận được từ bộ cảm biến tại một thời điểm, hay nói cách khác số chiều của vector ngẫu nhiên rất nhỏ, lúc này chi phí tìm ma trận nghịch đảo của tương đối nhỏ, đồng thời các ma trận khác đã có rồi, việc tính toán còn lại chỉ là nhân ma trận sẽ nhanh hơn rất nhiều so với bài toán gốc nhân rồi tính một ma trận nghịch đảo rất lớn!
Giả định tiếp tục với ví dụ trên với:
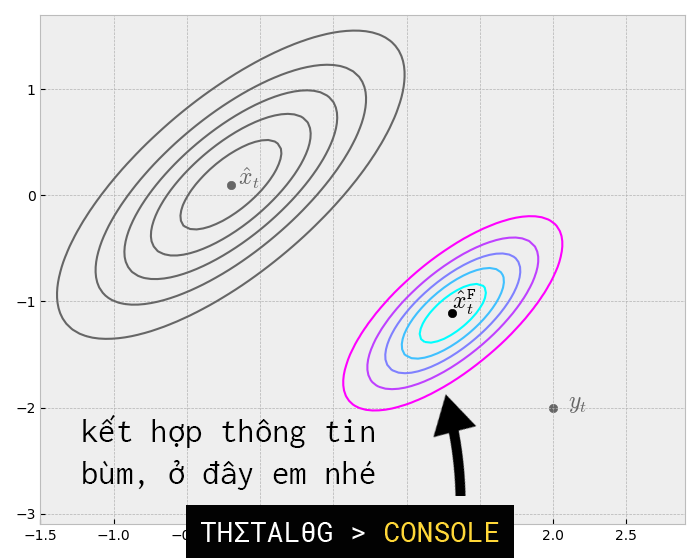
Cuối cùng chúng ta cũng kết hợp được hai thông tin thành một thông tin mới hữu ích hơn để hiểu rõ về trạng thái của phi thuyển!
Ngay bây giờ chúng ta muốn dự đoán tương lai, trạng thái của phi thuyền sẽ đi đâu về đâu?
Trạng thái mới có thể biểu diễn dưới dạng trạng thái dịch chuyển và bị thêm một ít nhiễu từ trạng thái cũ:
Với:
- : ma trận mô hình chuyển đổi trạng thái.
- : ma trận mô hình điều khiễn đầu vào (dùng để kết hợp với từ người dùng).
- : vector điều khiển (người dùng nhập để kết hợp với ).
- : vector ngẫu nhiên nhiễu hệ thống (system noise), có phân bố chuẩn nhiều chiều .
Thường thì và bị khuyết, được xem là sửa lỗi hệ thống được thêm bởi người dùng, việc thêm vào cũng giống như việc thêm một đại lượng không đổi vào các công thức, việc biến đổi với các tính chất kỳ vọng và hiệp phương sai không khó. Nên để gọn phần trình bày dưới đây chúng ta sẽ xem như bị khuyết.
Vì vậy chúng ta xem như là:
Tuy nhiên chúng ta lại trực nhớ ra rằng, xác suất tiên nghiệm của chúng ta đã được thay thế bằng một xác suất hậu nghiệm nhìn có vẻ hợp lí hơn, do đó chúng ta biểu diễn dưới dạng:
Vì tổ hợp tuyến tính của các phân bố chuẩn là phân bố chuẩn, nên cũng là phân bố chuẩn, mà là phân bố chuẩn nhiều chiều thì chúng ta cần tìm hai tham số, kỳ vọng và ma trận hiệp phương sai.
May mắn thay, nhờ vào tính chất kỳ vọng và ma trận hiệp phương sai với vector ngẫu nhiên, ta có:
Đặt hệ số này được gọi là Kalman Gain, chúng ta có thể viết phân bố mới ở dạng gọn hơn:
Viết gọn lại:
(với là ma trận đơn vị)
Giả định rằng ta có:
Chúng ta có phân bố dự đoán tương lai như sau:
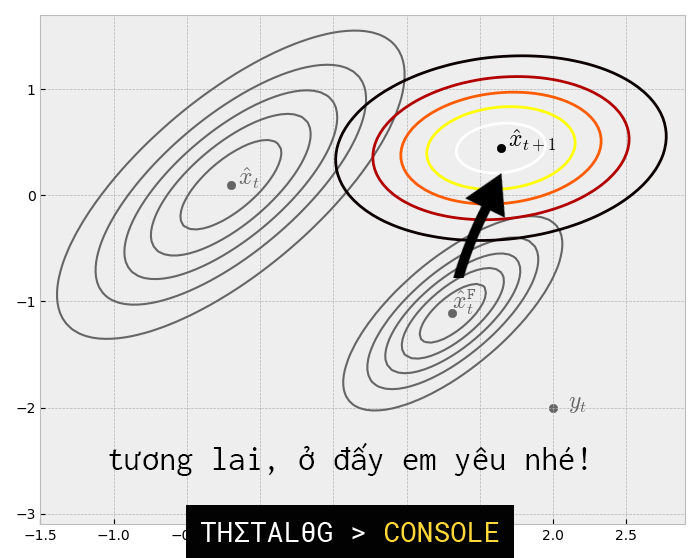
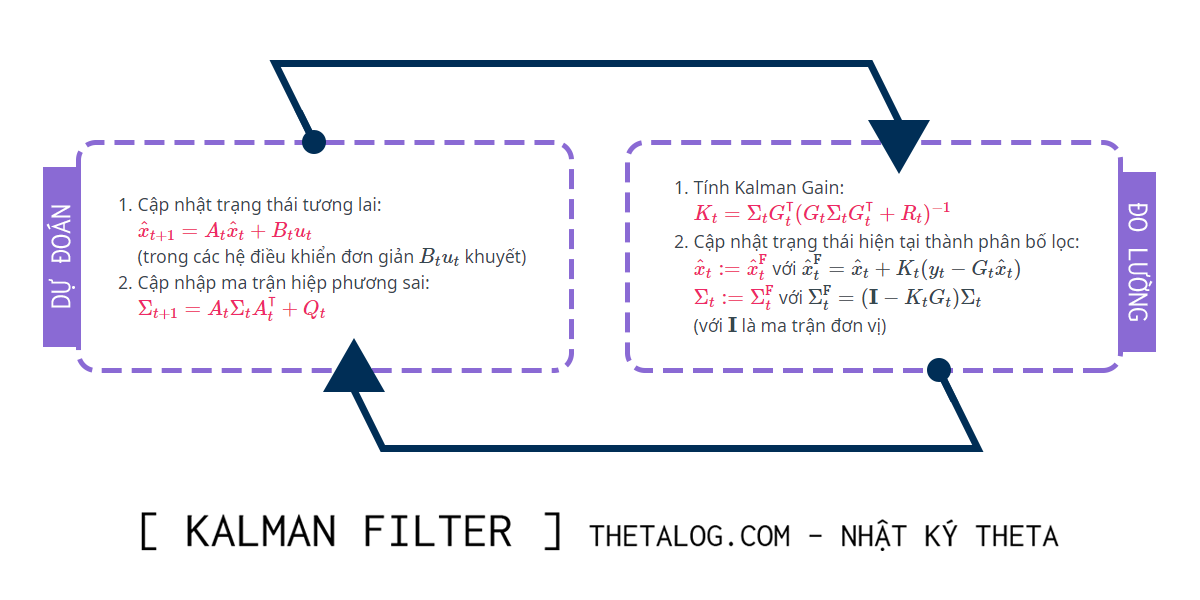
2. Tổng kết và thủ tục đệ quy:

Kalman Filter sẽ thực hiện thủ tục đệ quy như gồm 2 thủ tục “đo lường” và “dự đoán”:
Thủ tục cập nhật đo lường (Measurement):
- Tính Kalman Gain:
- Cập nhật trạng thái hiện tại thành phân bố lọc:
với
với
(với là ma trận đơn vị)
- Tính Kalman Gain:
Dự đoán tương lai (Prediction):
- Cập nhật trạng thái tương lai:
(trong các hệ điều khiển đơn giản khuyết) - Cập nhập ma trận hiệp phương sai:
- Cập nhật trạng thái tương lai:
3. Cài đặt thuật toán và những vấn đề tính toán
Chi phí tính toán của thuật toán chủ yếu đến từ việc nhân và lấy ma trận nghịch đảo, như đã trình bày ở trên nếu như vector ngẫu nhiên quan sát được có số chiều nhỏ hơn nhiều so với chúng ta có thể tính toán bằng khai triển ma trận nghịch đảo như trên để tính toán hiệu quả.
Việc thiết lập ma trận , , , thường là do kỹ sư thiết lập dựa trên hiểu biết về dữ liệu của mình (các đại lượng vật lý, kinh tế,… thường có mối quan hệ mật thiết với nhau). Tuy nhiên có rất nhiều phương pháp học tham số cho mô hình Kalman Filter mà bạn đọc có thể tự tham khảo thêm (trong cộng đồng lý thuyết điều khiển thì vấn đề này được biết đến như systems identification, thường cách đơn giản nhất là bạn sẽ thu thập dữ liệu, xây dựng hàm mất mát và giải bài toán bình phương tối tiểu).
Nếu chú ý kĩ bạn sẽ thấy ma trận hiệp phương sai chỉ phụ thuộc vào không phụ thuộc vào sự kiện quan sát được trả về từ bộ cảm biến , trong một số trường hợp đặc biệt, chúng ta có thể tính toán ma trận này trước khi xuất hiện, việc này đòi hỏi bạn cần hiểu về sự hội tụ của ma trận xảy ra như thế nào (bạn đọc quan tâm tìm hiểu thêm về Ricatti equations).
Trong những ứng dụng thương mại lớn, Kalman Filter được thiết kế “tương đối phức tạp” vì tính ổn định tính toán số, thời gian chạy,… Nếu quan tâm đến những vấn đề này, bạn đọc có thể truy cập vào kho tài liệu đồ sộ về Kalman Filter ở đây: http://www.cs.unc.edu/~welch/kalman/
Hiện tại có rất nhiều thư viện cài đặt Kalman Filter sẳn như OpenCV (C/C++, Python), filterpy (Python), Matlab.
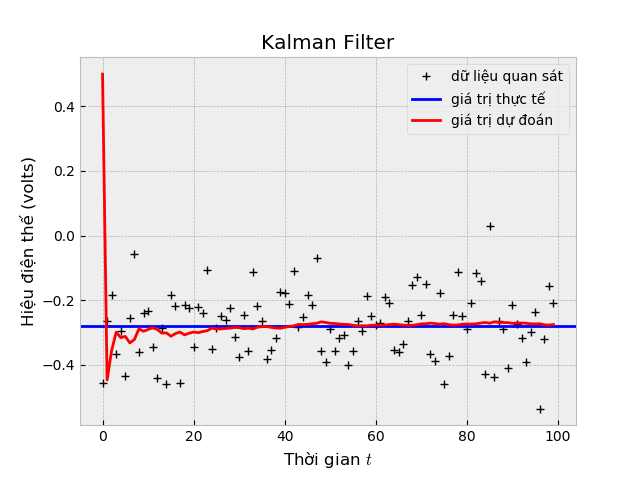
Dưới đây là một bài mô phỏng đơn giản trên phân bố chuẩn 1 chiều dựa trên ví dụ của Greg Welch và Gary Bishop, giả sử có một nguồn điện với hiệu điện thế không thay đổi theo thời gian (cho lý tưởng là vậy nhé, nghĩa là volts mãi luôn). Bạn thực sự không biết giá trị hiệu điện thế của nguồn điện này đâu, bạn quyết định đi tìm giá trị này như một thú vui lúc rảnh rỗi. May mắn thay, bạn tìm được một cái vôn kế đời cũ không chính xác. Rất may là nhà sản xuất có để lại thông tin, vôn kế này bị nhiễu theo phân bố . Biết rằng mỗi lần đo kế tiếp, hiệu điện thế không đổi gì nhiều (thiết lập ma trận chuyển trạng thái ), mô hình quan sát của được đo từ vôn kế bằng giá trị thực tế cộng thêm nhiễu (giả định ma trận ). Không rõ độ lệch chuẩn của nguồn điện phóng ra khi sử dụng bình thường là bao nhiêu, bạn tạm đoán là volt (thiết lập ma trận ), tại thời điểm ban đầu chưa biết bạn đoán nguồn điện volt (thiết lập ).
Trong ví dụ này, mình sẽ cài đặt phần mô phỏng nhìn hơi dỏm một tí (vì đây là phân bố chuẩn 1 chiều không cần phải cài đặt rườm rà như vậy, hơn nữa việc giả lập có thể tạo luôn một lần thay vì gọi từng lần). Tuy nhiên mình mong muốn mã nguồn này có thể phản ánh được nội dung trong bài viết, vì thế chúng ta cùng thử nhé:
Kết quả (quan sát từ Terminal bạn có thấy gì đặc biệt không nào?):
4. Phần mở rộng và ứng dụng:
Kalman Filter phiên bản cơ bản bị giới hạn bởi giả định mô hình tuyến tính, dưới đây là hai mô hình phi tuyến quan trọng của Kalman Filter:
- Extended Kalman filter
- Unscented Kalman filter (bản nâng cấp từ EKF, tốt hơn)
Ứng dụng Kalman Filter rất rộng, thuật toán 60 năm tuổi nhưng vẫn tiếp tục ảnh hưởng đến cuộc sống của chúng ta hàng ngày:
- Ứng dụng vào các bộ GPS thương mại. IEEE
- Xe tự láy (Advanced Driver Assistance Systems) Why should car drivers love Kalman filtering?
- Thực tế ảo Human Motion - MIT Press
- Robotic SLAM (simultaneous localization and mapping)
- Dự báo thời tiết 2016 Weather forecasting
- Theo dõi đối tượng trong thị giác máy tính Object Tracking - MathWorks
- Kinh tế lượng Advances in Econometrics - Cambridge
5. Tổng kết
Kalman Filter là một thuật toán dự đoán chuỗi thời gian. Ý tưởng cơ bản thuật toán dựa trên định lý Bayes cho phân bố chuẩn nhiều chiều. Thuật toán có nhiều ứng dụng quan trọng trong xử lý tín hiệu, kinh tế lượng,…
Bài viết gói gọn trong Kalman Filter cơ bản, các phần mở rộng EKF, UKF được ứng dụng rộng rãi hơn trong các ứng dụng phức tạp.
Chúc bạn có nhiều trải nghiệm thú vị với Kalman Filter!
Tham khảo
- Greg Welch, Gary Bishop. An Introduction to the Kalman Filter. https://www.cs.unc.edu/~welch/media/pdf/kalman_intro.pdf
- Thomas J. Sargent John Stachurski. A First Look at the Kalman Filter. Quantitative Economics. https://lectures.quantecon.org/jl/kalman.html
- Bzarg. How a Kalman filter works, in pictures. https://www.bzarg.com/p/how-a-kalman-filter-works-in-pictures/
- Matlab. Understanding Kalman Filters, Part 1: Why Use Kalman Filters?. https://www.youtube.com/watch?v=mwn8xhgNpFY
- Wikipedia contributors. “Kalman filter.” Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 1 Nov. 2018. Web. 5 Nov. 2018.
- Chris Bracegirdle. Bayes’ Theorem for Gaussians. September 2010. http://web4.cs.ucl.ac.uk/staff/C.Bracegirdle/bayesTheoremForGaussians.pdf
- Kevin P. Murphy. Multivariate Gaussians. Last updated September 28, 2007. https://www.cs.ubc.ca/~murphyk/Teaching/CS340-Fall07/reading/gauss.pdf
- Wikipedia contributors. “Woodbury matrix identity.” Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 4 Nov. 2018. Web. 13 Nov. 2018.
- Bilgin Esme. Kalman Filter For Dummies. http://bilgin.esme.org/BitsAndBytes/KalmanFilterforDummies
- Statlect. Covariance matrix. https://www.statlect.com/fundamentals-of-probability/covariance-matrix
- Greg Welch, Gary Bishop. The Kalman Filter. http://www.cs.unc.edu/~welch/kalman/
- Simon D. Levy. The Extended Kalman Filter: An Interactive Tutorial for Non-Experts. https://home.wlu.edu/~levys/kalman_tutorial/