

Dirichlet Process Mixture Model
Nội dung bài viết
Dirichlet Process Mixture Model (DPMM) là một thuật toán phân cụm nằm trong nhóm thống kê phi tham số Bayesian, sỡ dĩ gọi là phi tham số vì bạn không cần phải thiết lập tham số (nhưng không có nghĩa là mô hình không có tham số). Mô hình này được ứng dụng nhiều vào trong các bài toán phân cụm khi chưa biết trước số cụm, đôi lúc dùng để xấp xĩ hàm mật độ,…
Dirichlet Process Mixture Model (DPMM) có nhiều ứng dụng thực tiễn, đặc biệt trong bài toán phân tích cụm khi chưa biết số cụm (khi mà lượng dữ liệu lớn và số chiều cao). Dẫu có rất nhiều phương pháp được thiết kế để “đoán số cụm” của dữ liệu, song phần lớn hướng tiếp cận chủ yếu được xây dựng như là một “mẹo giải” (heuristic), phương pháp này khá đặc biệt vì hướng tiếp cận được xây dựng chặt chẽ từ mô hình lý thuyết.
Mô hình vô hạn của Dirichlet Process Mixture Model khởi tạo một lượng lớn số cụm không cần thiết và sử dụng chúng để thoát khỏi cục bộ địa phương. Hãy cùng nhau khám phá thuật toán này nhé!
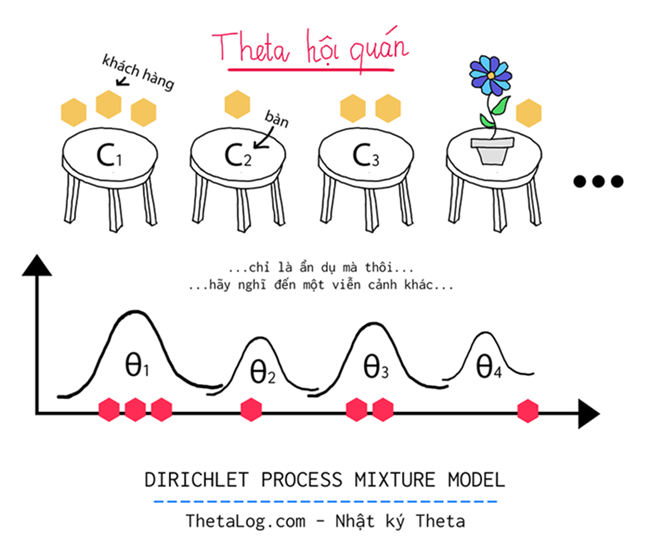
1. Bài toán quá trình nhà hàng Trung Hoa
Chinese Restaurant Process
Trước khi đến với bài toán gốc, chúng ta hãy cùng nhau khảo sát bài toán “quá trình nhà hàng trung hoa” vì nó có liên hệ đến ý tưởng mô hình hóa của mô hình “vô số cụm” trong bài toán sắp tới.
Tưởng tượng một nhà hàng kỳ lạ:
- Nhà hàng có vô hạn chiếc bàn.
- Mỗi chiếc bàn có thể chứa vô hạn khách.
Mỗi khách đến với nhà hàng và ngồi vào một cái bàn với cơ hội:
- Ngồi vào một bàn cc đang có người ngồi: p(ngồi ở bàn c)=ncα+∑cnc
- Ngồi vào một bàn mới chưa có người ngồi: p(ngồi ở bàn mới)=αα+∑cnc
Với α được là một tham số tỉ lệ (còn gọi là “độ tập trung”), α càng lớn thì có vẻ như rằng nhà hàng phải mở nhiều bàn hơn, α càng nhỏ thì có vẻ nhà hàng mở với số lượng bàn ít hơn, nc là số lượng người hiện tại đang ngồi ở bàn c, do đó ∑c là số khách hàng đang ngồi tại nhà hàng Trung Hoa.
Quá trình trên được gọi là “quá trình nhà hàng Trung Hoa được định nghĩa bởi [Aldous 1985, Pitman 2006].
Bài toán này thật sự không có gì đặc biệt, nếu như chúng không thử mô phỏng nó tí xem.
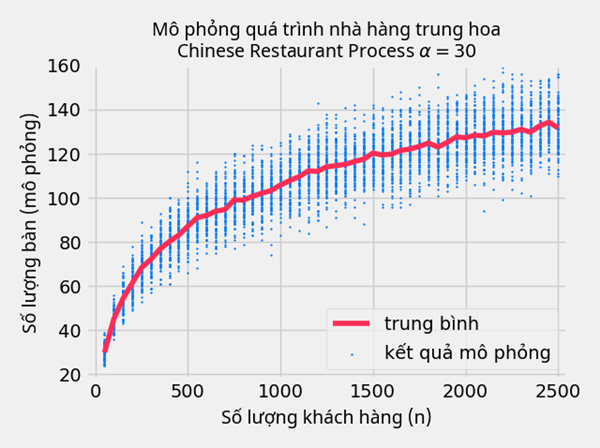

Liệu bạn có cảm giác rằng số lượng bàn tăng theo hàm logarít không?
Đặt q là biến ngẫu nhiên số bàn cần phải trang bị khi biết hệ số α và n khách hàng tới nhà hàng, những nhà toán học xấp xĩ được kỳ vọng và phương sai của q của nhà hàng kỳ lạ này:
- Kỳ vọng: E[q|α,n]≈αln(1+nα)
- Phương sai: V[q|α,n]≈αln(1+nα)
Thử vẽ hình ra xem liệu công thức trên có đúng không nào!
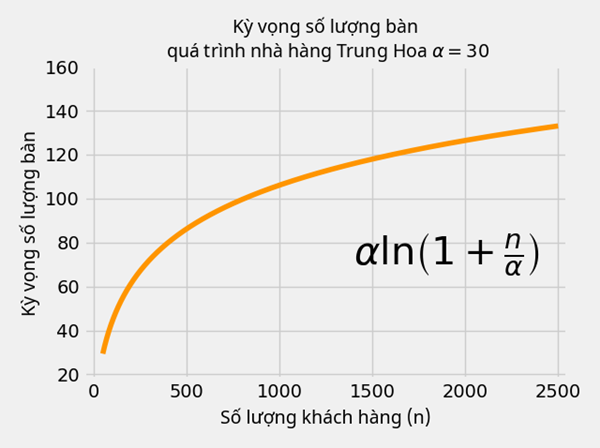
Liệu việc tăng số bàn khá chậm theo hàm logarít này có dẫn đến điều gì đặc biệt không?
Hãy cùng nhau đi làm bồi bàn vài bữa ở “Nhà hàng Trung Hoa” để hiểu quá trình trong nhà hàng này cùng phép ẩn dụ “khách là điểm” còn “bàn là cụm”… Thật lạ, ông chủ cứ bảo “bàn thì anh không thiếu (nhà hàng kỳ quặc vô hạn bàn) mà nhiều thì anh không có (thực tế chỉ hữu hạn dao động trong nhường dăm ba cái là cùng)“… thật kỳ quặc mà, hãy chờ xem…
2. Dirichlet Process
Quá trình Dirichlet (Dirichlet Process) là một quá trình ngẫu nhiên thường được sử dụng trong các mô hình thống kê phi tham số Bayesian. Dirichlet Process được định nghĩa bởi [Ferguson 1973] như là một phân bố trên một phân bố khác (tạm gọi là “phân bố nền” - base distribution). Nó là một trong những nền tảng quan trọng của một số mô hình thống kê phi tham số Bayesian.
Dirichlet Process xác định bởi hai tham số là phân bố nền H và một số dương α được gọi là độ tập trung. Gọi G là một biến ngẫu nhiên có phân bố Dirichlet Process cho phân bố H cùng hệ số α ta có thể viết:
G∼DP(α,H)
Lúc này với mỗi một tập hữu hạn phần tử phân hoạch không gian xác suất A1,…,Ar, vectơ ngẫu nhiên (G(A1),…,G(Ar)) được phân bố ngẫu nhiên theo G, ta gọi biến ngẫu nhiên G được phân bố theo Dirichlet Process với phân bố nền H cùng độ tập trung α hay G∼DP(α,H) nếu vectơ ngẫu nhiên này thỏa:
G(A1),…,G(Ar))∼Dir(αH(A1),…,αH(Ar))
Trong đó Dir là phân bố Dirichlet (tập các trường hợp xảy ra của phân bố này thỏa mỗi vectơ có tổng bằng 1 nằm trong một đơn hình (hay còn gọi là simplex), hàm mật độ cần tham số của một vectơ hệ số dương).
Dirichlet Process có nhiều cách để xây dựng một quá trình xác suất để thỏa mãn những yêu cầu trên. Hai phép “ẩn dụ” phổ biến nhất của quá Dirichlet Process mà bạn đọc nên quan tâm là:
- Chinese restaurant process.
- Stick-breaking construction.
Phần này chúng ta sẽ không phân tích chi tiết ở đây.
Ngay bây giờ, chúng ta sẽ tìm hiểu Dirichlet Process một cách trực cảm! Chúng ta sẽ tìm hiểu Dirichlet Process theo sự thay đổi tham số H và α để hiểu “đôi phần về quá trình này”!
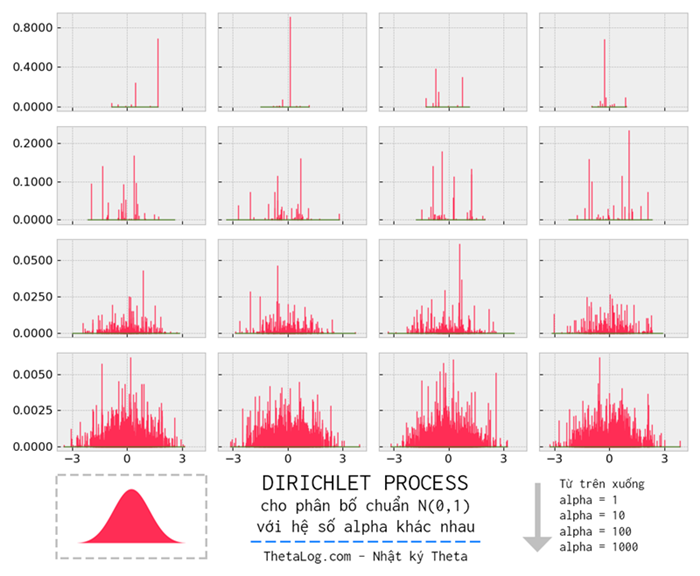
Hình trên là Dirichlet Process với tham số phân bố H là phân bố chuẩn N(0,1) với hệ số α thay đổi từ trên xuống 1,10,100,1000 khi lấy 1500 mẫu, nhận xét:
- Dirichlet Process làm “rời rạc hóa” phân bố nền, H có thể là một phân bố liên tục và trơn, tuy nhiên phân bố DP(α,H) thì lại rời rạc, không trơn hơn phân bố nền.
- Khi tham số α (độ tập trung) tiến về 0 hay α→0, phân bố Dirichlet Process càng “rời rạc”, tập trung tại một vài trường hợp có thể xảy ra của phân bố H.
- Khi tham số α (độ tập trung) tiến về ∞ hay α→∞, phân bố Dirichlet Process càng “liên tục”, ít tập trung hơn tại một vài trường hợp có thể xảy ra phân bố H hơn, giá trị α càng cao thì phân bố Dirichlet Process càng giống phân bố H.
3. Mô hình sinh dữ liệu của mô hình trộn theo cách nhìn từ Dirichlet Process
Trong phần này chúng ta sẽ thảo luận về mô hình sinh dữ liệu của mô hình trộn (Mixture Model) theo cách nhìn từ Dirichlet Process.
Trong xác suất thống kê, một mô hình trộn là một mô hình xác suất để biểu diễn cho mô hình tổng thể bằng sự hiện diện của các phân bố con theo hệ số trộn. Hay nói cách khác, một phân bố tổng quát có thể biểu diễn bằng việc trộn của các phân bố con, giả sử có K phân bố con, mỗi phân bố con thứ k được cho bởi một tham số θi:
p(x|θ)=K∑k=1πkpk(x|θk)
Ví dụ, mô hình trộn của phân bố chuẩn được xác định bởi tham số kỳ vọng μ và ma trận hiệp phương sai Σ, ta có thể viết lại:
p(x|θ)=K∑k=1πkN(x|μk,Σk)

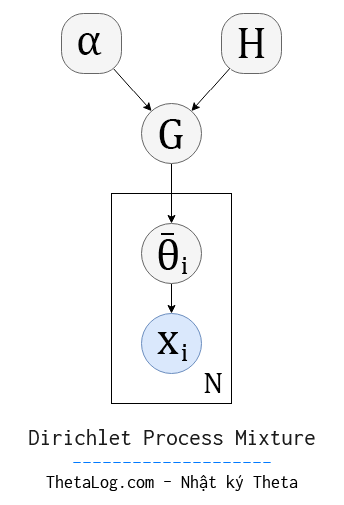
Giả sử mỗi tham số θk được sinh ra từ một phân bố H nào đó.
Hãy nghĩ về một quá trình Dirichlet Process nọ cho phân bố H và tham số α sinh ra các bộ tham số ¯θi nào đó N lần, mỗi tham số ¯θi này sẽ dùng để sinh ra các điểm dữ liệu xi.
Như ta đã biết, Dirichlet Process sẽ làm rời rạc hóa phân bố gốc và tạo một phân bố mới tập trung tại một số giá trị phân bố H.
Tập các bộ tham số {¯θ1,…,¯θN} có những bộ tham số được lặp đi lặp lại nhiều lần! Giả sử tập bộ tham số được lặp đi lặp lại gồm có K bộ tham số khác nhau ¯θi∈{θ1,…,θK}, chúng ta có thể hình dung quá trình này sinh ra một tập dữ liệu có mô hình trộn K cụm.
4. Dirichlet Process Mixture Model
Dirichlet Process Mixture Model là mô hình mà giả thuyết là phân bố trộn của dữ liệu được sinh ra được xem như là một quá trình Dirichlet bởi một phân bố tham số của θ.
Mô hình Bayesian này có nhiều cách để tìm tham số. Một trong những cách thông dụng nhất là dùng kỹ thuật MCMC (Markov Chain Monte Carlo) hoặc dùng kỹ thuật biến phân (Variantional Inference).
Mỗi một cách định nghĩa mô hình đồ thị khác nhau sẽ dẫn đến chúng ta có cách giải quyết bài toán khác nhau. Định nghĩa mô hình đồ thị như phần 3 chúng ta vẫn có thể giải quyết bài toán. Tuy nhiên mô hình trên không hiệu quả cho bài toán này, bạn đọc có thể tham khảo 8 thuật toán MCMC của Radford M. Neal, mô hình đồ thị như phần 3 chính là thuật toán thứ 1 trong bài báo “Markov Chain Sampling Methods for Dirichlet Process Mixture Models”.
Với mô hình trộn K cụm sinh N điểm dữ liệu xi, mỗi điểm dữ liệu gán nhãn thuộc về cụm zi chúng ta có thể biểu diễn mô hình trộn hữu hạn Bayesian như sau (đã gắn tiên nghiệm cho các tham số cần thiết):
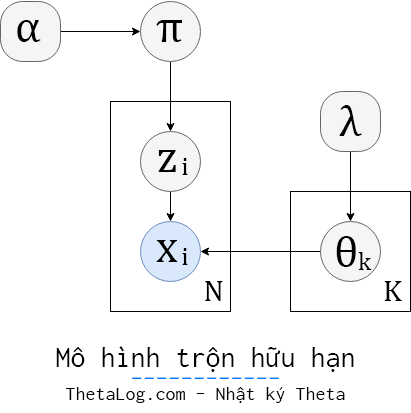
Với mô hình trên, khi biết điểm dữ liệu xi thuộc về cụm k và có tập tham số θ ta có:
p(xi|zi=k,θ)=p(xi|θk)
Gọi π là một vectơ k thành phần có tổng là 1 thể hiện hệ số trộn của mô hình trộn, lúc này xác suất dữ liệu thuộc về cụm k tương ứng là:
p(zi=k|π)=πk
Xem π được sinh ra từ phân bố Dirichlet với tham số α (ký hiệu 1K thể hiện một vectơ K thành phần đều là 1):
p(π|α)=Dir(π|(α/K)1K)
Mỗi tham số θk được sinh ra từ một phân bố θk∼H(λ), để thuận lợi cho việc tính toán phân bố tiên nghiệm p(θk|λ) sẽ được chọn liên hợp với phân bố p(xi|θk). (từ thuật toán 1 đến 3 trong bài báo của Radford M. Neal là trường hợp dùng tiên nghiệm liên hợp, từ thuật toán số 4 trở về sau dùng cho trường hợp không sử dụng tiên nghiệm liên hợp).
Lúc này khi biết xi thuộc cụm θk, ta có thể viết p(xi|θk) được sinh ra từ phân bố xi∼F(θzi) với F là phân bố con được dùng trong mô hình trộn.
Nhờ tính có thể “hoán đổi” được (exchangeable random variables) trong trường hợp bài toán này, và giả sử rằng phân bố H thì liên hợp với F, chúng ta có thể sử dụng Collapsed Gibbs Sampling (lược bỏ đi π và θk) trong mô hình, việc chúng ta cần tìm bây giờ là đi tìm zi.
Loại π và θk ra khỏi công thức Gibbs Sampling, phân bố có điều kiện của z khi biết trước tập dữ liệu x cùng với cụm của các điểm dữ liệu khác tỉ lệ với:
p(zi=k|z−i,x,α,λ)∝p(zi=k|z−i,α)p(xi|z−i,x−i,zi=k,λ)
(từ phần này về hai phần sau nk,−i là số lượng điểm thuộc cụm k ngoại trừ điểm xi)
Bởi tính có thể “hoán đổi” được, giả sử zi là điểm dữ liệu cuối cùng được tạo ra (hay “khách hàng đến nhà hàng cuối cùng” trong phép ẩn dụ bài toán nhà hàng Trung Hoa) mà công thức p(zi=k|z−i,α) trở nên “dể chịu” hơn rất nhiều.
Vì sao cần phải sử dụng tiên nghiệm liên hợp (conjugate prior) trong bài toán này? Hãy quan sát công thức màu xanh p(xi|z−i,x−i,zi=k,λ) đây là một công thức “khó tính” trong nhiều trường hợp!
4.1 (hữu hạn) Trường hợp cho biết trước số cụm
Trong trường hợp biết trước số cụm K, ta có:
p(zi=k|z−i,α)=nk,−i+αKα+N−1
Và:
p(xi|z−i,x−i,zi=k,λ)∝∫p(xi|θk)[∏j≠i,zj=kp(xj|θk)]H(θk|λ)dθk
Mã giả thuật toán:
clusters← tạo K cụm, mỗi cụm là một phân bố (cùng tiên nghiệm liên hợp tương ứng)
For i trong 1 đến N lặp: {
zi←lấy ngẫu nhiên thuộc từ 1 đến K
Thêm xi vào cụm clusters[zi], cập nhật các tham số cần thiết
}
For iter trong 1 đến maxiter lặp: {
For i trong 1 đến N lặp: {
Xóa xi trong cụm clusters[zi], cập nhật các tham số cần thiết
Tính và chuẩn hóa p(zi|z−i,x,α,λ), gọi phân bố rời rạc này là p(znew|.)
Lấy mẫu znew∼p(znew|.)
Thêm xi vào cụm clusters[znew], cập nhật các tham số cần thiết
}
}
RETURN z
4.2 (vô hạn) Trường hợp chưa biết trước số cụm
Trong phần này chúng ta kí hiệu k∗ là cụm mới và θ∗ là tham số cụm mới, k là cụm cũ và θk là tham số cụm cũ.
Trong trường hợp chưa biết số cụm, giả sử khởi tạo có K cụm, tại mỗi lần chúng ta cho phép điểm đó nhảy sang các cụm hiện có, hoặc sang một cụm mới. Khi phân tích K→∞ [Tài liệu 1,Neal 2000] ta có
- Nếu là cụm cũ trước đó: p(zi=k|z−i,α)=nk,−iα+N−1
- Nếu là cụm mới: p(zi=k∗|z−i,α)=αα+N−1
Và:
- p(xi|z−i,x−i,zi=k,λ)∝∫p(xi|θk)[∏j≠i,zj=kp(xj|θk)]H(θk|λ)dθk
- p(xi|z−i,x−i,zi=k∗,λ)∝∫p(xi|θ∗)[∏j≠i,zj=kp(xj|θ∗)]H(θk|λ)dθ∗=∫p(xi|θ∗)H(θ∗|λ)dθ∗=p(xi|λ)
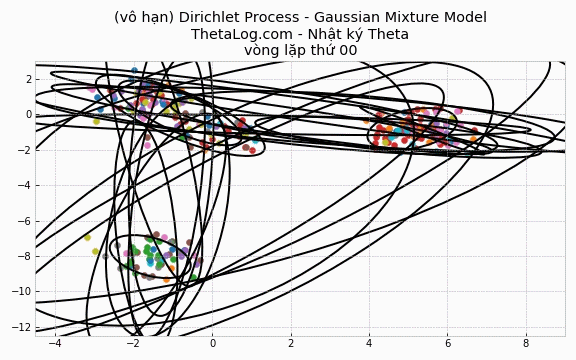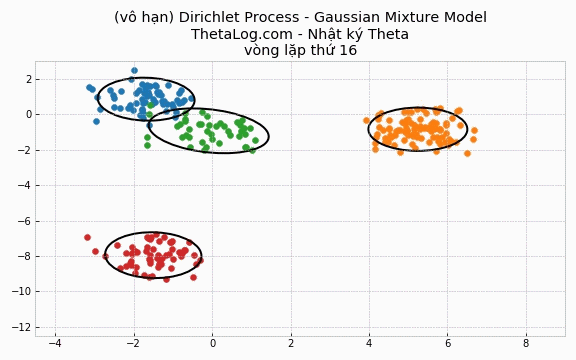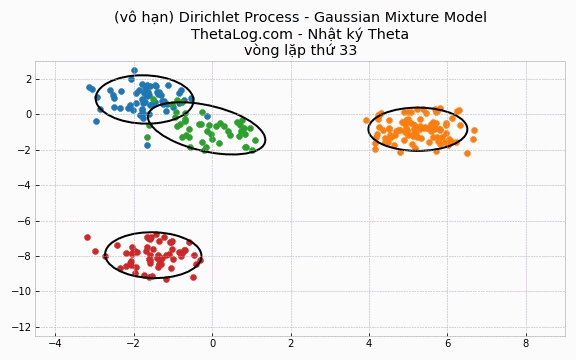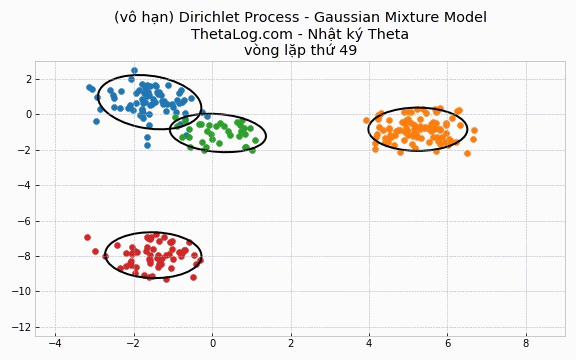
Trong mô hình này, mỗi vòng lặp ngoài những cụm đang hiện hành ra thì chúng ta sẽ xét thêm liệu có nên thêm cụm mới vào. Dẫu K→∞ là một điều gì đó nghe như “phim kinh dị”, bởi vì chúng ta biết rằng hầu hết trong số chúng là những cụm không cần thiết, tuy nhiên may mắn thay hầu hết những cụm thừa không cần thiết sẽ bị loại bỏ sau một vài vòng lặp! Nếu những giả định của chúng ta là hợp lý với quá trình sinh dữ liệu, khi lặp đủ nhiều, mô hình này K sẽ lặp quanh quẩn trong một khoảng nào đó.
Mã giả thuật toán:
clusters← tạo K cụm, mỗi cụm là một phân bố (cùng tiên nghiệm liên hợp tương ứng)
For i trong 1 đến N lặp: {
zi←lấy ngẫu nhiên thuộc từ 1 đến K
Thêm xi vào cụm clusters[zi], cập nhật các tham số cần thiết
}
For iter trong 1 đến maxiter lặp: {
For i trong 1 đến N lặp: {
Xóa xi trong cụm clusters[zi], cập nhật các tham số cần thiết
If cụm vừa xóa rỗng:
Xóa luôn cụm đó khỏi clusters, cập nhật các tham số cần thiết
Tính và chuẩn hóa p(zi|z−i,x,α,λ), gọi phân bố rời rạc này là p(znew|.)
Lấy mẫu znew∼p(znew|.)
If znew là cụm mới:
Thêm một cụm mới vào clusters, cập nhật các tham số cần thiết
Thêm xi vào cụm clusters[znew], cập nhật các tham số cần thiết
}
}
RETURN z
5. Thử cài đặt thuật toán DPMM với phân bố trộn Gaussian
Trong phần này chúng ta sẽ cài đặt DPMM (Dirichlet Process Mixture Model) cho phân bố Gaussian.
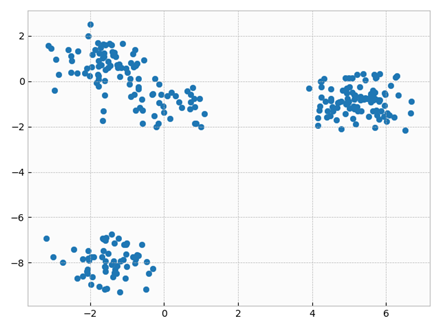
5.1 Tạo tập dữ liệu nhân tạo
Vẽ X:
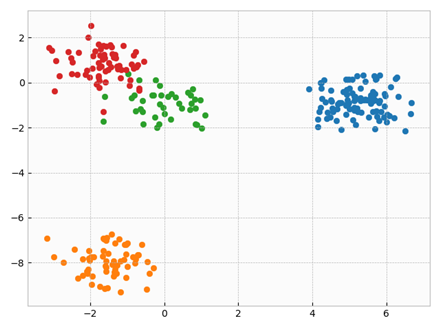
Vẽ X với nhãn của cụm:
5.2 Cài đặt Gaussian (với Gaussian-Wishart làm phân bố tiên nghiệm)
Phần cài đặt phân bố p(xi|z−i,x−i,zi=k,λ) với dùng phân bố cụm Gaussian (dùng Gaussian-Wishart làm tiên nghiệm cho tham số) cho từng phân bố con trong mô hình trộn.
Bạn đọc tham khảo phần chi tiết cài đặt: Tại đây
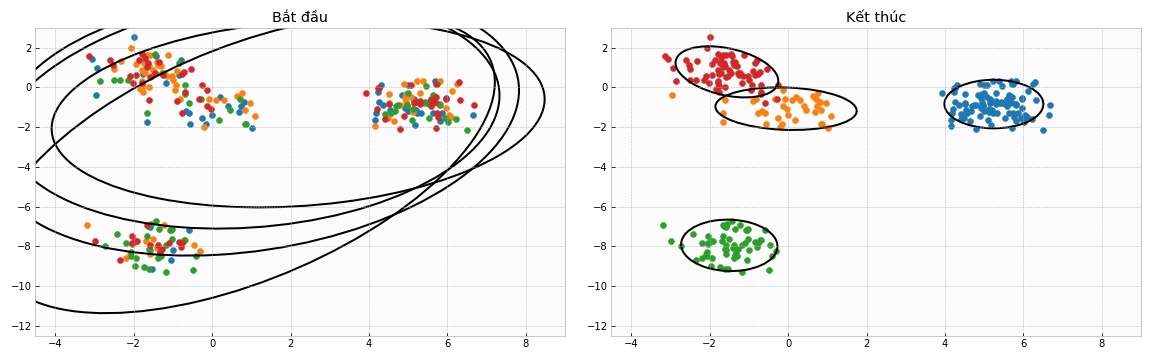
5.3 Cài đặt trường hợp DP-GMM hữu hạn
Trong trường hợp DPMM hữu hạn, chúng ta sẽ khai báo số lượng K cụm có trong mô hình.
Thử chạy thử xem:
Vẽ thử ra kết quả:
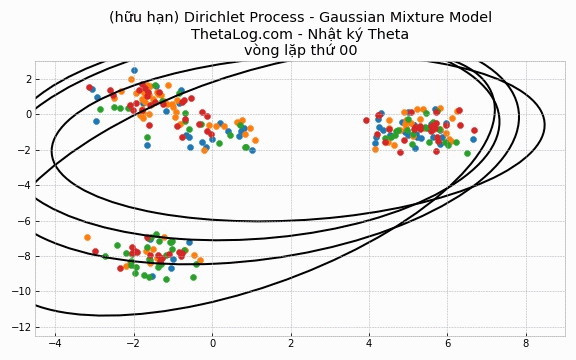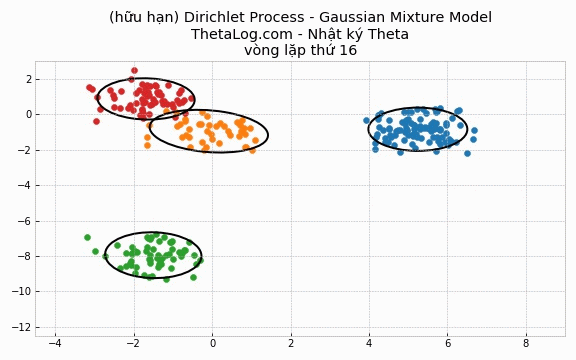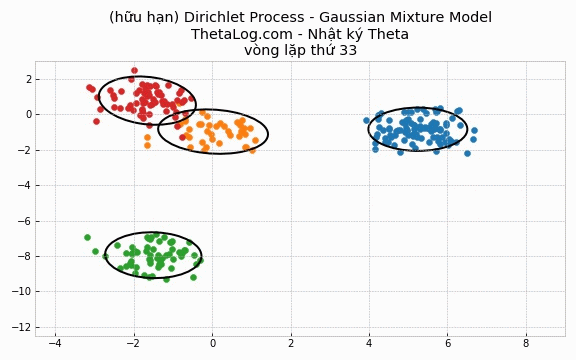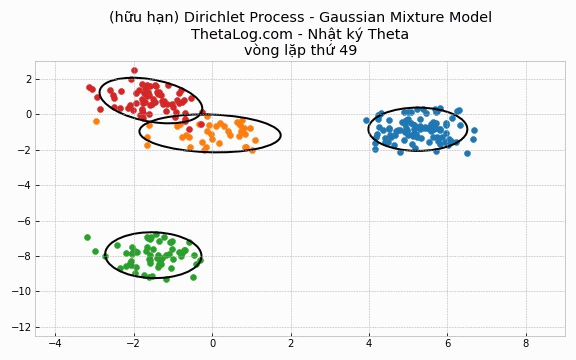
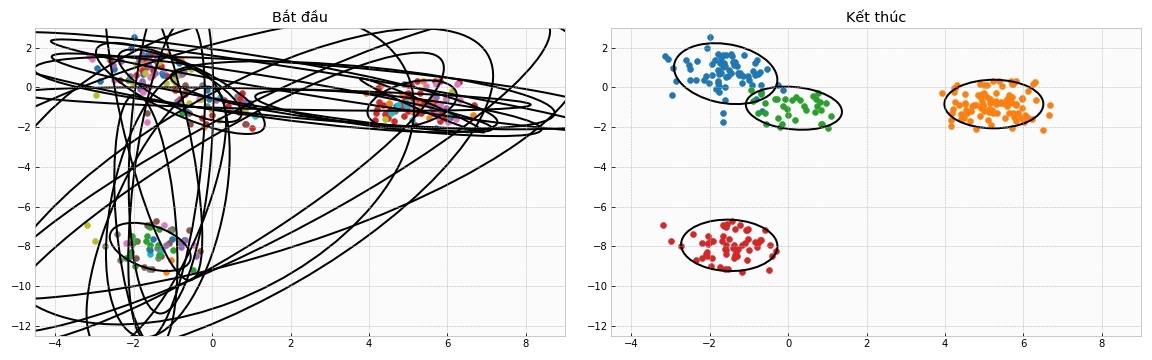
5.4 Cài đặt trường hợp DP-GMM vô hạn
Trong trường hợp DPMM vô hạn, chúng ta sẽ khai báo số lượng cụm K là một số lớn ngay từ đầu.
Thử chạy thử xem:
Vẽ thử ra kết quả:
6. Phần kết
Github (chứa Jupyter Notebook): Tại đây
Trong bài viết này ThetaLog tìm hiểu và cài đặt DPMM với trường hợp Gaussian hay nói cách khác DP-GMM (Dirichlet Process Gaussian Mixture Model) qua MCMC (Collapsed Gibbs Sampling) có dùng tiên nghiệm liên hợp (conjugate prior) tương ứng. Những trường hợp khác không sử dụng tiên nghiệm liên hợp (conjugate prior) bạn đọc quan tâm có thể tìm hiểu qua [Tài liệu 1, Neal 2000]. Ngoài ra còn nhiều hướng giải quyết tìm tham số khác như biến phân (Variational Inference), sử dụng A* và Beam Search để tìm tham số,… bạn đọc quan tâm có thể tìm hiểu thêm.
Dirichlet Process Mixture Model là một mô hình phân cụm phi tham số thú vị. Hi vọng bài viết mang lại nhiều thông tin bổ ích cho bạn đọc! Chúc bạn có những giây phút vui vẻ bên thuật toán!
ThetaLog - Nhật ký Theta! Lê Quang Tiến - quangtiencs
Tham khảo
- Radford M. Neal. Markov Chain Sampling Methods for Dirichlet Process Mixture Models. Journal of Computational and Graphical Statistics. http://www2.stat.duke.edu/~scs/Courses/Stat376/Papers/DirichletProc/NealDirichletJCGS2000.pdf
- Kevin P. Murphy. Machine Learning A Probabilistic Perspective. The MIT Press. ISBN 978-0-262-01802-9
- Matt Gormley. The Dirichlet Process (DP) and DP Mixture Models. 10-708 Probabilistic Graphical Models. http://www.cs.cmu.edu/~epxing/Class/10708-16/slide/lecture18-DP.pdf
- Khalid El-Arini. Dirichlet Processes A gentle tutorial. https://www.cs.cmu.edu/~kbe/dp_tutorial.pdf
- Michael I. Jordan. Dirichlet Processes, Chinese Restaurant Processes, and all that. http://videolectures.net/icml05_jordan_dpcrp/
- Yee Whye Teh. Dirichlet Processes: Tutorial and Practical Course. https://www.stats.ox.ac.uk/~teh/teaching/npbayes/mlss2007.pdf
- Yee Whye Teh. Bayesian Nonparametrics. http://mlss.tuebingen.mpg.de/2013/2013/slides_teh.pdf
- Kurt Miller. Dr. Nonparametric Bayes Or: How I Learned to Stop Worrying and Love the Dirichlet Process. https://people.eecs.berkeley.edu/~jordan/courses/294-fall09/lectures/nonparametric/slides.pdf
- Eric Xing. Probabilistic Graphical Models. Bayesian Nonparametrics: Dirichlet Processes. http://www.cs.cmu.edu/~epxing/Class/10708-14/lectures/lecture19-npbayes.pdf