

BPR Bayesian Personalized Ranking
Nội dung bài viết
Bayesian Personalized Ranking (BPR) là một hướng tiếp cận để tối ưu tham số của một số mô hình hệ khuyến nghị thông dụng từ thông tin phản hồi tiềm ẩn được đề xuất bởi Rendle và cộng sự nhằm giải những khó khăn gặp phải bởi dữ liệu của bài toán này.
Hệ thống khuyến nghị (Recommender Systems, hoặc cũng có thể gọi Hệ gợi ý) là một chủ đề được nghiên cứu rất năng động. Trong bài toán này, thông tin mà chúng ta thu thập được có thể trong hai viễn cảnh sau đây:
- Thông tin phản hồi rõ ràng (explicit feedback): người dùng đánh giá sản phẩm qua việc chấm điểm (ví dụ số sao ứng dụng).
Ưu điểm: thông tin được đưa ra trực tiếp từ người dùng (không phải tự phỏng đoán).
Nhược điểm: trải nghiệm người dùng rườm rà phức tạp, tiêu cực từ thành kiến người dùng (ví dụ: một sản phẩm bị đánh giá 1⁄5 sao ngay từ đầu khả năng cao là sẽ ít được người khác ngó ngàng tới nữa). - Thông tin phản hổi tiềm ẩn (implicit feedback): người dùng xem sản phẩm, tương tác với sản phẩm,…
Ưu điểm: mọi thông tin có thể thu thập ngầm mà không gây phiền đến người dùng.
Nhược điểm: suy luận theo kiểu phỏng đoán, thông tin không rành mạch.
Trong công nghiệp, hệ khuyến nghị đóng vai trò quan trọng trong tăng doanh thu dịch vụ (ví dụ: dự đoán mặt hàng người dùng muốn mua trong thương mại điện tử, nhạc & phim với các dịch vụ giải trí,…). Hầu hết các ứng dụng thông thường chọn hướng tiếp cận thu thập thông tin phản hồi tìm ẩn, ví như “mua” từ Amazon, “click” từ “Google Advertisement”, “thả tim” từ “Instagram”…
Trong bài viết này, chúng ta sẽ tìm hiểu những khó khăn của bài toán xây dựng hệ khuyến nghị từ thông tin phản hồi tiềm ẩn từ người dùng, đồng thời tìm hiểu hướng tiếp cận Bayesian Personalized Ranking (BPR) giải quyết bài toán này ra sao!
1. Vì sao huấn luyện một hệ khuyến nghị lại khó?
Giả sử bạn sở hữu một trang web thương mại điện tử lớn ThetaShop. Mỗi lần người dùng vào xem một sản phẩm sẽ có hàng loạt gợi ý những sản phẩm khác, hy vọng rằng những sản phẩm mà chúng ta gợi ý sẽ là những sản phẩm mà người dùng muốn mua. Như vậy, nếu hệ khuyến nghị hoạt động hiệu quả thì doanh thu của ThetaShop sẽ tăng đáng kể!
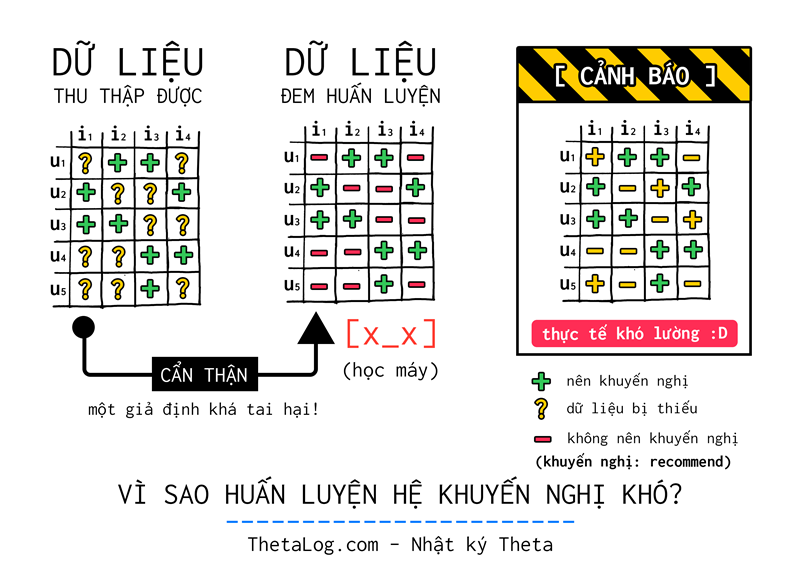
Những kỹ sư khoa học dữ liệu sẽ là những người đi xây dựng các mô hình toán học cho các hệ khuyến nghị này. Thật không may, một tình huống đáng tiếc xảy ra, bài toán của chúng ta bị ảnh hưởng bởi dữ liệu thu thập rất nhiều!
Trong bài toán này, thông thường bạn chỉ thu thập được dữ liệu trường hợp nào “nên khuyến nghị” (mang tính tích cực), hầu như không, ít khi bạn thu thập hoặc nhận biết được dữ liệu trường hợp nào “không nên khuyến nghị” (mang tính tiêu cực). (vì thế đôi lúc người ta gọi đây là bài toán một lớp one class recommender system vì chỉ có một loại thông tin có thể quan sát được)
Giả sử bài toán như sau:
- ThetaShop có sản phẩm khác nhau, gọi đó là tập với là tập sản phẩm (items).
- ThetaShop có người dùng, gọi đó là tập với là tập người dùng (users).
Và lúc này kí hiệu:
- : những trường hợp nên khuyến nghị (ví dụ tương tác người dùng mua sản phẩm ).
- : những trường bị thiếu do không quan sát được. Liệu chúng ta có thể kết luận gì?
- : những trường hợp không nên khuyến nghị (vì có lẽ người dùng sẽ không thích sản phẩm này).
| Thực tế khó lường, rất chi phũ phàng |
|---|
|
Thông thường, các thuật toán máy học cho mô hình khuyến nghị cổ điễn thường giả định những trường hợp không quan sát được là những trường hợp không nên khuyến nghị. Tất nhiên, nếu học trên dữ liệu như thế sẽ làm hệ khuyến nghị trở nên “quá khớp” (overfitting), hay nói cách khác dự đoán trên tập dữ liệu huấn luyện rất tốt nhưng trên dữ liệu chưa bao giờ nhìn thấy rất tệ. Phần lớn các thuật toán đều có một số giải pháp để tránh việc này thông qua “bình thường hóa” (regularization).
Tuy nhiên chúng ta ở đây sẽ tìm hiểu một hướng tiếp cận khá thú vị với bài toán này Bayesian Personalized Ranking!
2. Bayesian Personalized Ranking
Một cửa hàng ThetaShop trực tuyến muốn đưa ra danh sách các sản phẩm mà người dùng muốn mua.
Gọi:
- : tập tất cả người dùng. Ví dụ:
- : tập tất cả sản phẩm. Ví dụ:
Trong viễn cảnh này là tập phản hồi từ người dùng.
Tác vụ của hệ khuyến nghị (recommender system) là đưa ra xếp hạng được cá nhân hóa cho người dùng những sản phẩm mà người dùng có thể yêu thích.
Một xếp hạng các sản phẩm, có thể định nghĩa bằng một quan hệ toán học, quan hệ toán học ở đây trả lời cho câu hỏi có hay không quan hệ giữa hai đối tượng đang xét, gọi quan hệ trên là của tất cả sản phẩm. Lúc này ta ký hiệu khi người dùng thích sản phẩm hơn sản phẩm .
(lưu ý: ở đây xem như một ký hiệu, tránh nhầm lẫn, bài viết này dựa trên hệ ký hiệu bài viết gốc)
Quan hệ này thỏa:
[ totality - toàn phần ] Sản phẩm và nằm một trong hai trường hợp được thích hơn , hoặc sản phẩm được thích hơn .
[ antisymmetry - phi đối xứng ] Quan hệ phi đối xứng, nếu thích hơn thì không thể xảy ra thích hơn . Do đó ta quy định rằng nếu điều trên xảy ra thì và là một sản phẩm .
[ transitivity - tính bắc cầu ] Quan hệ bắt cầu, nếu người dùng thích sản phẩm hơn và thích sản phẩm hơn thì ta có thể suy ra người dùng thích hơn .
Để tiện lợi hơn, chúng ta cũng định nghĩa:
(ở đây là tập những sản phẩm mà người dùng đã thích (mua, thả tim,..), tương tự là tập người dùng có tương tác với sản phẩm hệ thống)
Thay vì tiếp cận theo hướng cũ, giả định toàn bộ trường hợp không quan sát được là trường hợp “không nên khuyến nghị”, hướng tiếp cận của BPR đặt ra một bài toán tối ưu hoàn toàn mới!
Gọi là dữ liệu huấn luyện ban đầu:
Tập là một tập gồm các bộ , ngữ nghĩa của các bộ ở đây là người dùng thì được giả định là thích hơn vì người dùng đã tương tác với mà không thấy tương tác gì với .
Hướng tiếp cận này có hai ưu điểm chính:
- Dữ liệu huấn luyện bao gồm các cặp (nên khuyến nghị - không nên khuyến nghị) và những trường hợp các cặp dữ liệu bị thiếu không đầy đủ sẽ không được đưa vào quá trình huấn luyện.
- Dữ liệu huấn luyện được tạo bởi mục tiêu xếp hạng (mục tiêu tối ưu này phù hợp với bài toán hơn) so với việc giả định ở các hướng tiếp cận cổ điển.
2.1 Bài toán tối ưu BPR Optimization Criterion
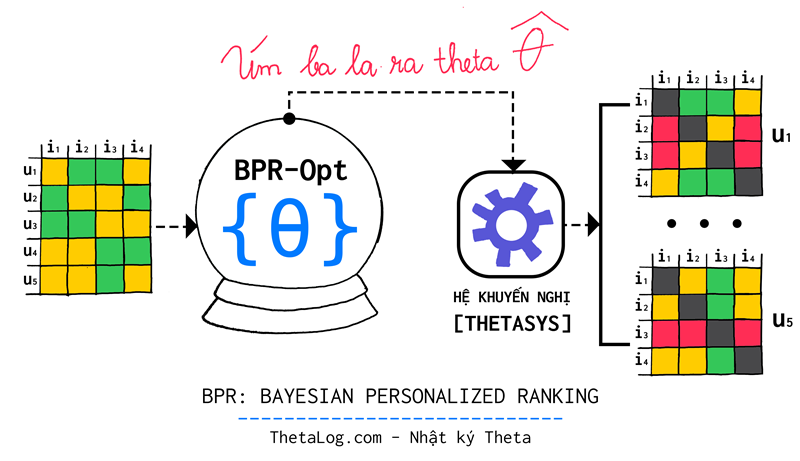
Giả sử chúng ta có một tập tham số , tập tham số biểu diễn vector tham số của một mô hình khuyến nghị (ví dụ Matrix Factorization).
Theo công thức Bayes, phân bố xác suất hậu nghiệm:
Do đóng vai trò như hằng số chuẩn hóa, do đó ta có thể viết phân bố hậu nghiệm lại ở dạng tỷ lệ:
Ký hiệu được xem như là cấu trúc về sự ưa thích của người dùng .
Phần sau đây, có lẽ sẽ có nhiều mẹo mực là chủ yếu, lý thuyết đẹp đẽ ngay từ đầu dường như không phải là trường hợp của bài này. Tuy nhiên, không cần cao siêu phức tạp, miễn giải quyết được tốt vấn đề thì nó vẫn là lời giải đẹp!
Vì tất cả người dùng được giả định hành động độc lập lẫn nhau. Chúng ta có thể viết hàm triển vọng (likelihood function trong công thức Bayes) lại dưới dạng tích:
Do đó ta có thể viết lại với mỗi người dùng :
Với là hàm thuộc tính (indicator function):
Đại ý ở đây mỗi tích là khả năng mà người dùng thích sản phẩm hơn sản phẩm .
Vì tính [ totality - toàn phần ] và [ antisymmetry - phi đối xứng ] ta có thể đơn giản công thức về:
Lúc này để ý, vì chúng ta đang xét những trường hợp những bộ , nên lúc này một quan hệ bất kì:
Vì thế chúng ta cần tìm cách “làm mềm” bài toán tại đây. Nếu không thì chỉ là hoặc mà thôi!
Đặt
Với là hàm sigmoid:
Với là một giá trị thực của hàm số theo tham số từ mô hình hệ khuyến nghị mà ta đang dùng thể hiện mức độ mà người dùng thích sản phẩm hơn , ở đây chúng ta xây dựng một mô hình linh hoạt có thể dùng cho nhiều mô hình bên dưới khác nhau.
Để tiện lợi, dể theo dõi hơn từ phần này về sau hiểu ngầm là .
Lúc này ta có thể hoàn tất viết hàm triển vọng dưới dạng:
Chúng ta đã bàn về hàm triển vọng, để hoàn tất mô hình suy luận Bayesian chúng ta cần thêm tiên nghiệm , xem như một vectơ ngẫu nhiên có phân bố chuẩn nhiều chiều với trung bình tại gốc tọa độ và ma trận hiệp phương sai , lúc này phân bố của :
Vì ta mong muốn tìm một khả năng xảy ra là cao nhất khi quan hệ xảy ra, tức tìm sao cho:
Tuy nhiên thay vì tối ưu trực tiếp, để tối ưu phân bố xác suất, chúng ta có thể dùng log loss để tối ưu nhanh hơn (vì sao? Đọc thêm về Cross Entropy trong Lý Thuyết Thông Tin - Information Theory). Đặt:
Đến đây, vẫn còn một ít “mẹo” cần vượt qua, tạm thời tại đây chúng ta xem như , và là một vectơ ngẫu nhiên chiều, do đó lúc này ta có:
Vì ta biết (với là ma trận và là định thức của ) do đó và .
Do đó:
Đặt lúc này xem đây như là tham số bình thường hóa mô hình, lúc này biểu thức màu cam sẽ là một hằng số phụ thuộc mà ta thêm vào, ta có:
Do đó bài toán tối ưu chúng ta qui về tìm cực đại của:
2.2 Thuật toán học BPR
BPR có hàm tối ưu mục tiêu là hàm khả vi, do đó chúng ta có thể dựa trên thuật toán hạ dốc (gradient descent) để xây dựng một phiên bản thuật toán tối ưu để cực đại .
Tuy nhiên do số lượng phần tử của tập có đâu đó khoảng bộ huấn luyện nên nếu dựa trên thuật toán hạ dốc gốc thông thường sẽ chạy rất chậm. Hơn nữa hãy tưởng tượng trường hợp sau, người dùng thích hơn phần lớn các trường hợp có trong tập dữ liệu (ví dụ chỉ mới mua mỗi ), nó dẫn đến vectơ gradient sẽ tương đối lớn, việc này dẫn đến chúng ta phải chọn một hệ số học learning rate đủ nhỏ (phụ thuộc nhiều vào dữ liệu), hơn nữa việc bình thường hóa chọn tham số regularization cũng sẽ khó hơn.
Do đó, hướng tiếp cận mà BPR sử dụng là SGD (stochastic gradient descent), thuật toán BPR tổng quát:
Khởi tạo
While chưa hội tụ:
chọn ngẫu nhiên từ
Endwhile
RETURN
Trong trường hợp mini-batch tại mỗi vòng lặp chúng ta tính vector gradient cho batch điểm.
2.3 Học mô hình hệ khuyến nghị với BPR
Bởi vì quá trình tối ưu của chúng ta dựa trên tập dữ liệu sinh ra từ các bộ , tuy nhiên hầu hết kết quả đầu ra của các thuật toán cổ điển không phải là một giá trị do đó chúng ta cần phải chuyển bài toán về dạng thích hợp hơn. Xem
Với là giá trị thể hiện mức độ yêu thích của người dùng với sản phẩm .
2.3.1 (BPR-MF) BPR cho Matrix Factorization
Với các hệ Matrix Factorization, bài toán dự đoán có thể được xem như là tác vụ ước lượng một ma trận kích thước được phân tích thành hai ma trận (kích thước ) và (kích thước ) thỏa:

Matrix factorization giả định rằng:
- Mỗi người dùng và sản phẩm có thể được mô tả bởi đặc trưng.
- đặc trưng ở đây có thể hiểu như là những nhân tố ở bên dưới thể hiện mối liên hệ giữa người dùng và sản phẩm. Ví dụ: hệ khuyến nghị về phim, đặc trưng có thể là: “hài hước”, “viễn tưởng”, “chiến tranh”, “tâm lý”,…
Với bài toán này, công thức dự đoán về độ yêu thích sản phẩm của người dùng được tính bởi:
Tham số mô hình cho bài toán này là . (với các phương pháp cổ điển chúng ta có thể giải quyết bài toán này với FunkMF, SVD++,…)
Với hướng tiếp cận BPR-MF chúng ta sẽ tìm qua việc tối ưu , với thuật toán LearnBPR giờ đây chúng ta chỉ còn thiếu .
Đặt là một phần tử trong ma trận . Ta có:
(mình không thích ký hiệu theo cách này của bài báo gốc cho lắm :D, lưu ý lúc này là một ma trận kích thước , với trong công thức trên là cột của ma trận )
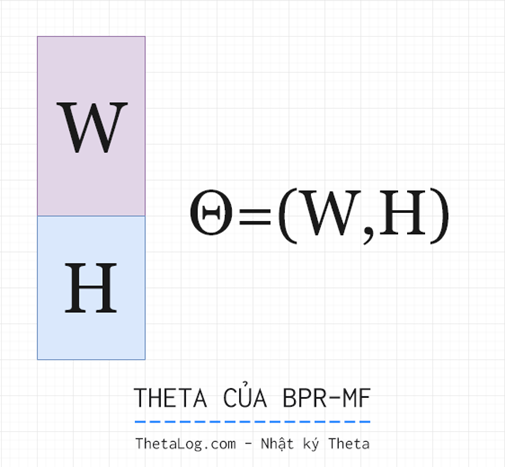
2.3.2 (BPR−kNN) BPR cho các hệ k người láng giềng
Bạn đọc quan tâm, có thể tìm đọc thêm bài báo gốc. ThetaLog sẽ không trình bày ở đây, vì có vẻ như hướng tiếp cận BPR cho hệ này không tăng hiệu quả của mô hình này. Nhưng cũng biết đâu bất ngờ, với vài tinh chỉnh, thuật toán này sẽ chạy tốt thì sao? :D
3. Thử cài đặt thuật toán BPR-MF và chạy thử trên tập dữ liệu MovieLens 100K
Dẫu thuật toán này xây dựng để giải quyết cho các bài toán hệ khuyến nghị tiềm ẩn. Tuy nhiên chúng ta vẫn có thể dùng để khuyến nghị cho các hệ phản hồi rõ ràng! Với những phản hồi rõ ràng, chúng ta chỉ cần chọn một ngưỡng để xem đó là những phản hồi tích cực nên khuyến nghị (ví dụ số sao >=3 chẳng hạn). Trong thực tế thì các hệ khuyến nghị đôi lúc kết hợp cả hai dạng thông tin để thu lại kết quả tốt nhất.
Nếu như bạn đang tìm một phiên bản cài đặt thuật toán BPR tốt bạn có thể tìm ở PreferredAI - cornac, có thể cài từ kênh conda-forge (với phân phối Anaconda Python).
Một phần mã nguồn tiền xử lí dữ liệu, đánh giá có tham khảo cài đặt từ Ethen (MingYu) Liu [5] với một vài chỉnh sửa mã nguồn tinh gọn, dể bảo trì hơn.
Phần learn_bpr_mf_mini_batch và learn_bpr_mf_sgd được cài đặt từ trang giấy trắng, trong thực hành thực tế, bạn chỉ cần chạy một thuật toán là đủ.
(thực ra thì learn_bpr_mf_sgd là phiên bản của learn_bpr_mf_mini_batch với batch=1 nhưng vì muốn giữ một phiên bản nguyên tác của bài báo nên mình thêm thuật toán learn_bpr_mf_sgd vào)
3.1 Tải dữ liệu từ mạng
| users | items | ratings | timestamp | |
|---|---|---|---|---|
| 0 | 196 | 242 | 3 | 881250949 |
| 1 | 186 | 302 | 3 | 891717742 |
| 2 | 22 | 377 | 1 | 878887116 |
| 3 | 244 | 51 | 2 | 880606923 |
| 4 | 166 | 346 | 1 | 886397596 |
3.2 Chuyển từ DataFrame ban đầu sang ma trận bài toán BPR
3.3 Tách ra thành tập dữ liệu Train & Test
Màn hình in ra thông tin:
BPR matrix with 82520 stored elements
Train matrix with 65641 stored elements
Test matrix with 16879 stored elements
3.4 Hàm bổ trợ (dự đoán, khuyến nghị, đánh giá)
3.5 (SGD) thuật toán học BPR-MF
3.6 (Mini-Batch) thuật toán học BPR-MF
3.7 Thử nghiệm
Thử nghiệm với phiên bản SGD (một điểm dữ liệu duy nhất):
Train: 0.841916
Test: 0.828263
Thử nghiệm với phiên bản mini batch (batch=1000 điểm):
Train: 0.842083
Test: 0.829265
Trong trường hợp thực hành trên một tập dữ liệu khác, bạn có thể thử phiên bản mini-batch vì thường nó hoạt động ổn định hơn, ở đây mình muốn giữ nguyên tác bài báo nên thêm phiên bản sgd.
Để dự đoán danh sách những sản phẩm khuyến nghị cho người dùng :
[257 287 180 99 49]
4. Phần kết
Github (chứa Jupyter Notebook): Tại đây
Trong bài viết này, ThetaLog giới thiệu những khó khăn của bài toán xây dựng hệ khuyến nghị từ thông tin phản hồi tiềm ẩn từ người dùng, đồng thời cài đặt thuật toán BPR-MF (Bayesian Personalized Ranking)!
Hy vọng bạn đọc sẽ có những giây phút thú vị với thuật toán!
ThetaLog - Nhật ký Theta
Lê Quang Tiến (quangtiencs)
Tham khảo
- Steffen Rendle, Christoph Freudenthaler, Zeno Gantner and Lars Schmidt-Thieme. BPR: Bayesian Personalized Ranking from Implicit Feedback.
- Weike Panand, Li Chen. GBPR: Group Preference Based Bayesian Personalized Ranking for One-Class Collaborative Filtering. Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence. https://www.aaai.org/ocs/index.php/IJCAI/IJCAI13/paper/viewFile/6316/7124
- Michael D. Ekstrand, Joseph A Konstan. Personalized Ranking (with Daniel Kluver). Matrix Factorization and Advanced Techniques - University of Minnesota. https://www.coursera.org/lecture/matrix-factorization/personalized-ranking-with-daniel-kluver-s3XJo
- Kim Falk. Practical Recommender Systems. Manning Publications.
- Ethen (MingYu) Liu. Bayesian Personalized Ranking. http://ethen8181.github.io/machine-learning/recsys/4_bpr.html
- Alfredo Láinez Rodrigo, Luke de Oliveira. Distributed Bayesian Personalized Ranking in Spark. https://stanford.edu/~rezab/classes/cme323/S16/projects_reports/rodrigo_oliveira.pdf