

Normalizing Flows và giới thiệu RealNVP
Nội dung bài viết
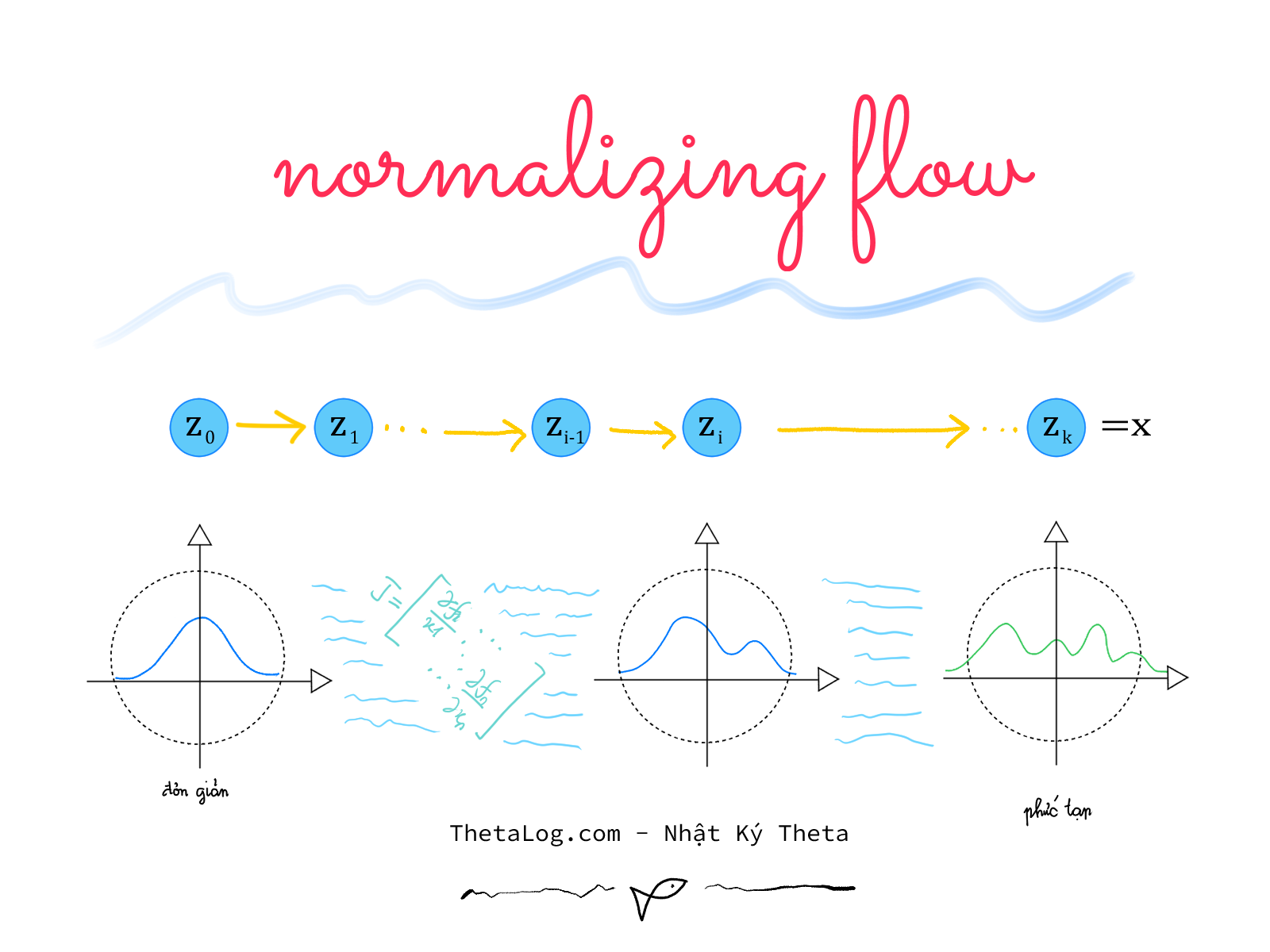
Normalizing Flows là nhóm mô hình sinh (generative models) mô hình hóa các phân bố phức tạp bằng cách sử dụng kỹ thuật đổi biến thông qua việc xây dựng các phép biến đổi khả nghịch phức tạp, linh hoạt. Trong bài viết này chúng ta sẽ tìm hiểu Normalizing Flows và một mô hình nổi tiếng khá phổ biến RealNVP.
Thế giới xác suất đắm chìm trong việc mô hình hóa tính chắc chắn của các sự kiện thông qua bản đồ niềm tin đặc tả bởi các con số, được xây dựng bởi các nhà toán học qua các phân bố xác suất.
Nhiều ứng dụng thú vị có thể xây dựng trên việc tính toán các phân bố xác suất phức tạp.
Ấy thế, thế giới thì quá đỗi tinh vi, phức tạp, rối rắm, khó lòng có thể mô hình hóa qua vài dòng công thức đơn giản mà quán triệt được hết vũ điệu hỗn độn và hài hòa của không gian sự kiện.
Hẳn vẫn có những trường hợp ta có thể xây dựng mô hình gần đúng và hữu dụng, như là người ta có thể mô hình hóa số lượng xe đi ngang qua một điểm trên con đường trong một khoảng thời gian cho trước với phân bố possion, hay mô hình hóa thời gian cho đến khi bạn bị tai nạn giao thông lần nữa với phân bố mũ,… Khi được sắp xếp một trình tự sự kiện xuất hiện hợp lý chúng ta sẽ có mô hình xác suất thống kê, các mô hình này có thể điều chỉnh sao cho gần với thực tế qua các tập tham số.
Tuy nhiên vẫn có những vấn đề hết sức phức tạp, chẳng hạn như ảnh số, một bức ảnh số trắng đen thông thường cũng đã hẳn chứa điểm ảnh hay MegaPixels, số lượng điểm ảnh đủ khổng lồ để dù một bộ óc thông thái siêu phàm cũng khó lòng viết ra công thức tường minh phân bố sinh ra ảnh khuôn mặt người mà có thể dừng bút đặt dấu chấm hết gói gọn trong vài trang giấy.
Tính toán, thao tác các phép toán trên phân bố phức tạp cũng rất khó khăn đầy thách thức. Một trong mẹo giải toán thú vị là chuyển bài toán khó thành bài toán dể hơn, liệu có cách nào giúp chúng ta chuyển phân bố phức tạp chiều thành một phân bố đơn giản chiều, khi mà phân bố đơn giản chiều chúng ta quá rạch ròi việc tính toán, việc tính toán phân bố phức tạp sẽ thông qua việc biến đổi kết quả từ phân bố đơn giản?
Normalizing Flows là một công cụ như thế, lấy ý tưởng chủ đạo của công thức đổi biến (change variable formula) biến đổi phân bố phức tạp thành phân bố đơn giản qua các phép biển đổi khả nghịch…
1. Mảnh ghép đầu tiên - công thức đổi biến:

1.1 Một ví dụ đơn giản minh họa:
Trong một đêm mưa gió giông bão, câu chuyện bắt đầu bằng mấy thí nghiệm và giả định vu vơ…
Giả sử ta có một biến ngẫu nhiên liên tục biết trước hàm mật độ p.d.f, có phân bố đều nằm trên giá hay .
Gọi là một biến ngẫu nhiên chưa biết hàm mật độ nhưng biết phép biến đổi đơn điệu nghiêm ngặt trên , biến đổi thành hay .
Mật độ điểm đã có sự thay đổi. Số lượng điểm trong khoảng nay đã không tương ứng với nữa, hiển nhiên, giờ đây số lượng điểm tương ứng với nếu ta phóng to và đếm từng điểm một.
Bảo toàn! Bạn chợt nhận ra, mọi thứ chẳng biến mất đi đâu cả, chỉ có mật độ là thay đổi. Thứ biểu diễn cho mật độ nhiều ít của một biến ngẫu nhiên liên tục là hàm mật độ. Thứ biểu diễn cho cơ hội của biến ngẫu nhiên xảy ra là phần diện tích tương ứng cho từng đoạn của biến ngẫu nhiên ấy.
Nói thế, thì vẫn chưa giải quyết được gì cả. Thế là ta lại viết suy nghĩ ấy ra dưới dạng công thức tường minh, phần diện tích ban đầu tương ứng với phần diện tích biến đổi có thể viết (và thêm vì tính đơn điệu nghiêm ngặt, mới viết được vầy):
Hay:
Một tí vẽ vời cho dể hình dung nào… (đáng lẽ ở đây phần diện tích sẽ rất nhỏ, tuy nhiên để dể hình dung thì ta chọn một đoạn lớn nhé):
Biến đổi tương đương ta có:
Do đó:
Công thức trên được gọi là công thức đổi biến cho phép chúng ta tìm được hàm mật độ của biến ngẫu nhiên liên tục chưa biết , khi biết hàm mật độ , phép biến đổi và hàm nghịch đảo tương ứng của .
Bài tập: thử thế vào công thức trên. Và vẽ thử ra hàm mật độ, xem có giống kết quả xấp xĩ hàm mật độ khi ta lấy mẫu không?
1.2 Công thức đổi biến cho vectơ ngẫu nhiên
Phần công thức sau cho vectơ ngẫu nhiên tạm thời sẽ không chứng minh. Bạn đọc quan tâm có thể tìm các tài liệu liên quan. Tuy nhiên hãy cẩn thận với tính đơn điệu trong phép biến đổi, tạm thời giản lược phần này, bạn đọc quan tâm sâu hơn về điều kiện cần của công thức này có thể tự tìm hiểu thêm…
| Công thức đổi biến cho vectơ ngẫu nhiên (Change of Variables Formula - Probability Topic) |
|---|
Gọi và là hai vectơ ngẫu nhiên liên tục chiều với . Công thức đổi biến cho ta biết hàm mật độ chưa biết khi biết và :
Ghi chú:
|
2. Mảnh ghép thứ hai - luồng khả nghịch:
Giờ đây ta như đứa trẻ, khám phá ra đôi điều hay ho như nhặt được mảnh vỏ sò ở bãi biển. Nhưng để rồi lại nhận thấy thế giới còn quá lớn và nhiều điều chưa biết…
Trong trường hợp trên, ta biết trước và tính toán được , , tuy nhiên trong trường hợp thực tế thì nào đâu có biết.
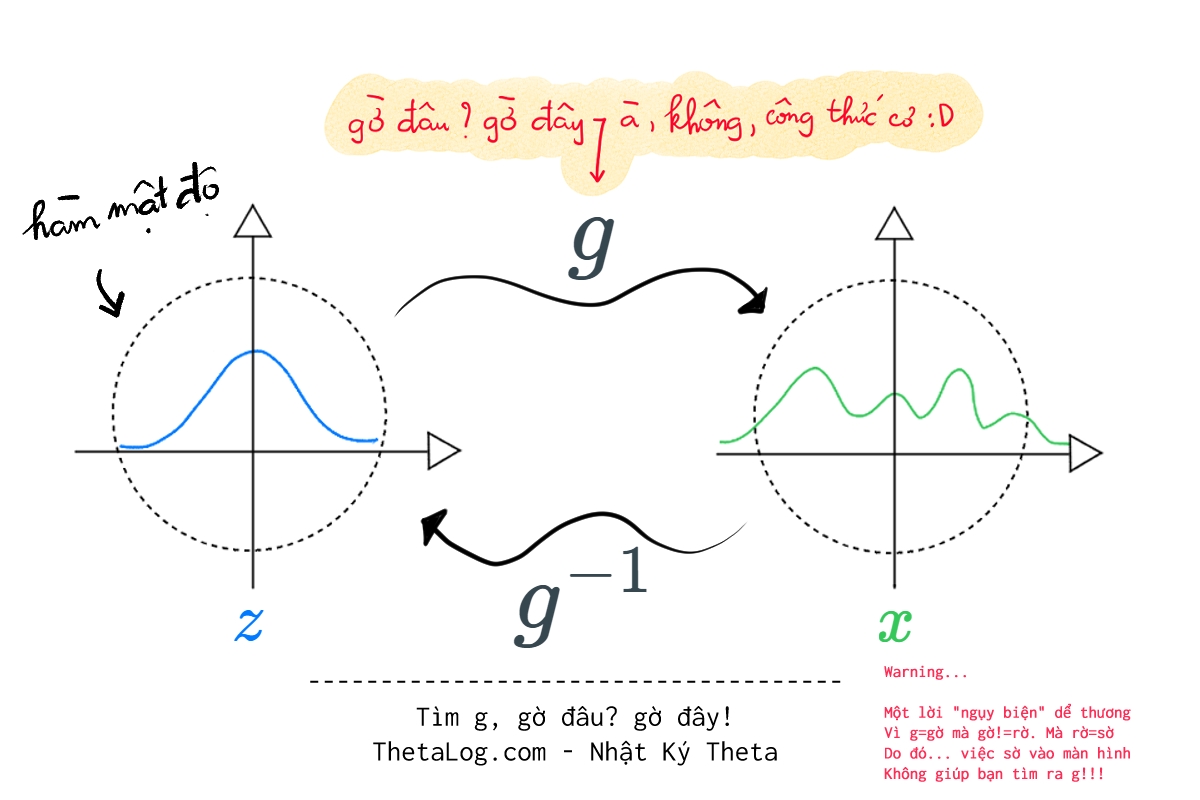
Thế ta lại mày mò việc mô hình hóa , liệu có cách nào xây dựng một linh hoạt ứng biến cho nhiều trường hợp khác nhau. Nhận ra:
1) Trước hết, một hàm khả nghịch có thể tham số hóa, tham số này có thể học được, nhờ đó sẽ linh động trong nhiều tình huống.
2) Thêm nữa, một hàm khả nghịch có thể xem như là một hàm hợp lồng nhau của nhiều hàm khả nghịch. Do tính chất đặc biệt hàm hợp, nếu hay nếu muốn tìm hàm nghịch . Quá thuận lợi! Trong trường hợp tổng quát, nếu thì .
3. Normalizing Flow
Normalizing Flow là sự kết hợp hai mảnh ghép ý tưởng (1) đổi biến (2) dùng luồng các phép biến đổi khả nghịch được tham số hóa và học từ dữ liệu để biến đổi phân bố đơn giản thành phân bố phức tạp, nhờ đó ta có thể tính toán xác suất trên hàm mật độ như lấy mẫu hoặc định lượng chắc chắn.
- Normalizing: chuẩn hóa, ý ở đây khi nói về công thức đổi biến. Qua phép biến đổi, bạn có một hàm mật độ được chuẩn hóa.
- Flows: luồng, ở đây đại ý nói về cách dùng chuổi các phép biến đổi khả nghịch.
Giả sử như tập dữ liệu chúng ta thu thập với mỗi là một vectơ biểu diễn dữ liệu. Để mô hình hóa mô hình sinh dữ liệu có nhiều cách. Một trong những cách phổ biến, chúng ta có thể áp dụng nguyên tắc hợp lý cực đại (maximum likelihood principle - đôi lúc có tài liệu dịch là triển vọng cực đại).
Nguyên tắc hợp lý cực đại có thể hiểu đơn giản như sau: dưới góc nhìn thống kê, một cách ngây ngô, ta có thể xem những gì ta quan sát được là bởi vì nó dể xảy ra nhất.
Trong trường hợp, dữ liệu được sinh ra độc lập và cùng một phân bố (i.i.d), ta có thể xem hàm cần tối ưu hợp lý cực đại dưới dạng tích của hàm mật độ , thường với các bài toán xác suất ta có thể tối ưu của hàm hợp lý, vì lúc này ta sẽ tách từ dạng tích thành tổng, hơn nữa sẽ an toàn tính toán số hơn do đôi khi giá trị hàm mật độ đôi lúc rất nhỏ gần .
Gọi là tập tham số cần tìm, là log hàm hợp lý (log likelihood function):
Hợp lý cực đại tương đương với tối ưu cực tiểu của hàm âm log hợp lý (negative loglikelihood), hay ta cần tìm một ước lượng sao cho:
Tuy vậy, từ lý thuyết đến thực tiễn là cả bầu trời… nan giải, đau đầu… Thì mọi việc sẽ không dể, vẫn có nhiều vấn đề về tính toán mà ta cần lưu ý:
Tính toán khả nghịch phải thuận tiện đơn giản: nếu bạn cần lấy mẫu thì cần (chỉ cần lấy mẫu và biến đổi sang ), trong khi các phép tính liên quan đến hàm mật độ bạn cần . Để tính toán nhẹ thì việc lấy định thức ma trận Jacobian phải nhanh, đây là một trong những phép toán nặng nề nhất trong bài này, khi mà phân bố chúng ta đối mặt có số chiều khổng lồ như ảnh số.
Phải đủ linh hoạt để biểu diển được quân bố quan tâm.
4. Giới thiệu mô hình RealNVP
Không lê thê dài dòng… giống như phim truyền hình dài tập nhưng cũng đôi phần hấp dẫn và gay cấn… như câu nói bất hủ trong văn học, thoáng chốc vài năm trôi qua, chỉ trong mấy phút đọc blog, từ khi ý tưởng Normalizing Flows hình thành nay đã trải qua nhiều thăng trầm mô hình hóa… sự cách tân luôn liên tục vận động thay đổi, sóng sau xô sóng trước, ấy thế lại có vài sự cách tân đáng chú ý! Nào hãy cùng nhau điểm qua kiến trúc RealNVP!
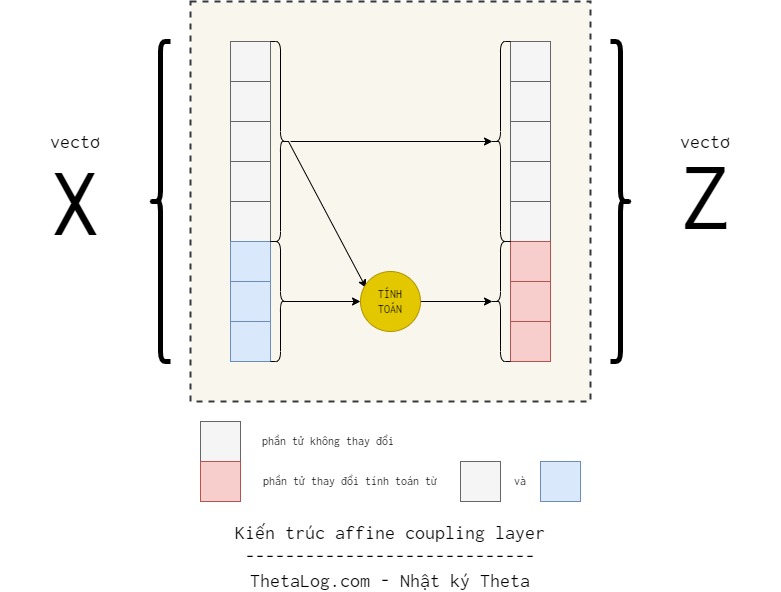
RealNVP (Real-valued Non-Volume Preserving) là một kỹ thuật trong nhóm các mô hình Normalizing Flow dùng các hàm khả nghịch lồng nhau là các lớp affine coupling layer. Sở dĩ gọi là affine coupling layer là vì phép biến đổi được tách ra làm một cặp, một phần thì giữ nguyên, một phần thì qua phép biến đổi affine.
Cụ thể là phép biến đổi:
- phần tử đầu của vectơ giữ nguyên.
- phần tử còn lại từ đến trải qua phép biến đổi affine với tham số được học từ phần đầu tiên.
Trong đó:
- và lần lượt là hàm tỷ lệ (scale) và tịnh tiến (translation) ánh xạ từ được mô hình hóa bởi mạng nơ-ron (neural network).
- là tích Hadamard. Nhân từng phần tử tương ứng của hai ma trận cùng chiều.
Khi đó phép biến đổi là:
Công thức (1) và (2) trên có thể viết gọn hơn để lúc mô hình hóa lúc lập trình trở nên đơn giản hơn bằng định nghĩa một binary mask bằng vectơ chỉ với và để xác định phần tử giữ nguyên và phần tử biến đổi:
Lúc này phần biến đổi ngược tương ứng:
Dể thấy và đều không có phép tính gì phức tạp.
Hơn nữa, điều thú vị trong cách mô hình hóa của RealNVP nằm ở việc tính định thức!
Ta có ma trận Jacobian lúc này như sau:
Ma trận lúc này là ma trận tam giác dưới, tính toán định thức, từ độ phức tạp rất cao tầm theo wikipedia giờ đây nhờ việc rơi vào trường hợp đặc biệt độ phức định thức của ma trận này có thể tính bằng tích đường chéo xuống còn :
Dể thấy, affine coupling layer có kiến trúc thuận tiện cho việc xây dựng mô hình Normalizing Flow.
Do trong affine coupling layer, một vài chiều không thay đổi. Điều này có thể bằng cách bố trí các lớp xen kẻ nhau, sao cho các thành phần không thay đổi trong lớp này sẽ được thay đổi ở lớp kế tiếp.
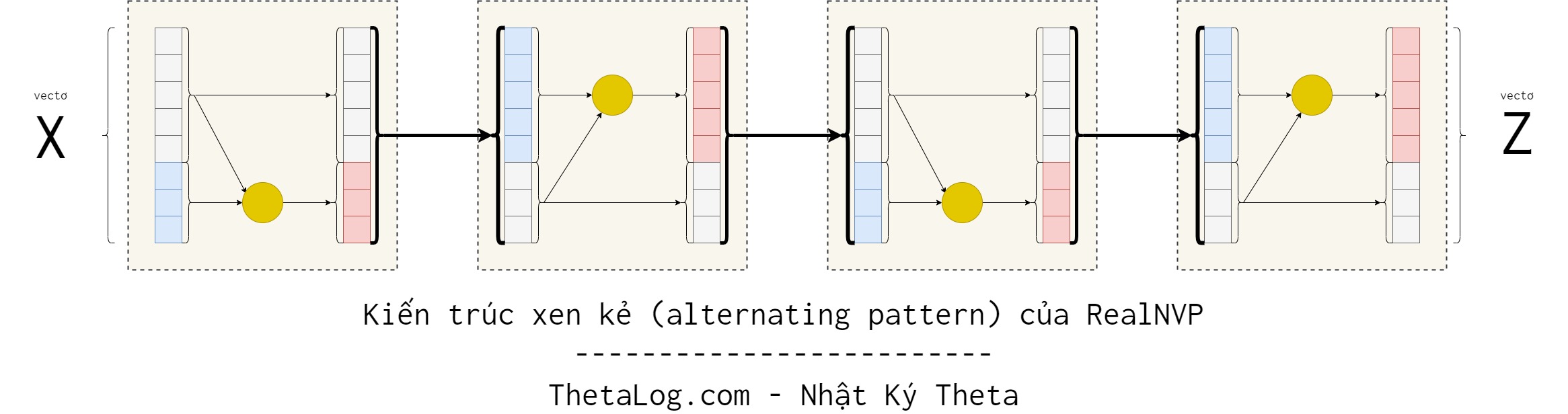
Khi đó việc tính toán định thức ma trận Jacobian từ các lớp cũng khá dể dàng, thật vậy:
Lúc này việc tính định thức bạn chỉ cần tính cho từng lớp (layer) xong rồi ghép lại thôi.
Nhìn chung kiến trúc RealNVP tương đối tốt và thuận lợi để tính toán.
Để cài đặt hoàn chỉnh RealNVP, có hai cách:
1) Tách vectơ ra thành từng phần như trên. Mình có đọc qua phần cài đặt của Tensorflow Probability theo hướng này. đọc tại dòng này
2) Cài đặt theo kiểu binary mask. Việc này giúp chúng ta tiện thử nghiệm hơn. (nếu ứng dụng cho các bài toán khác nhau, ảnh, âm thanh,… chỉ cần thay đổi binary mask).
ThetaLog quyết định chọn theo hướng thứ 2, bắt đầu vào việc nào:
Tái thiết lập lại thí nghiệm khi cần (mặc dù đã bật enable_op_determinism nhưng điều này còn phụ thuộc phần cứng chạy):
Numpy 1.21.5 set seed to 178
Tensorflow 2.8.0 set seed to 149
Tensorflow Probability 0.16.0
----------------------------
When the day becomes the night
And the sky becomes the sea,
When the clock strikes heavy
And there's no time for tea.
And in our darkest hour,
Before my final rhyme,
She will come back home to Wonderland
And turn back the hands of time.
Tạo dữ liệu nhân tạo:
Vẽ ra xem 4 tập dữ liệu nhân tạo trông thế nào nhé!
Hàm negative log likelihood:
Trong một xíu thời gian thưởng thức cốc trà… ngồi viết phần trực quan hóa nào…
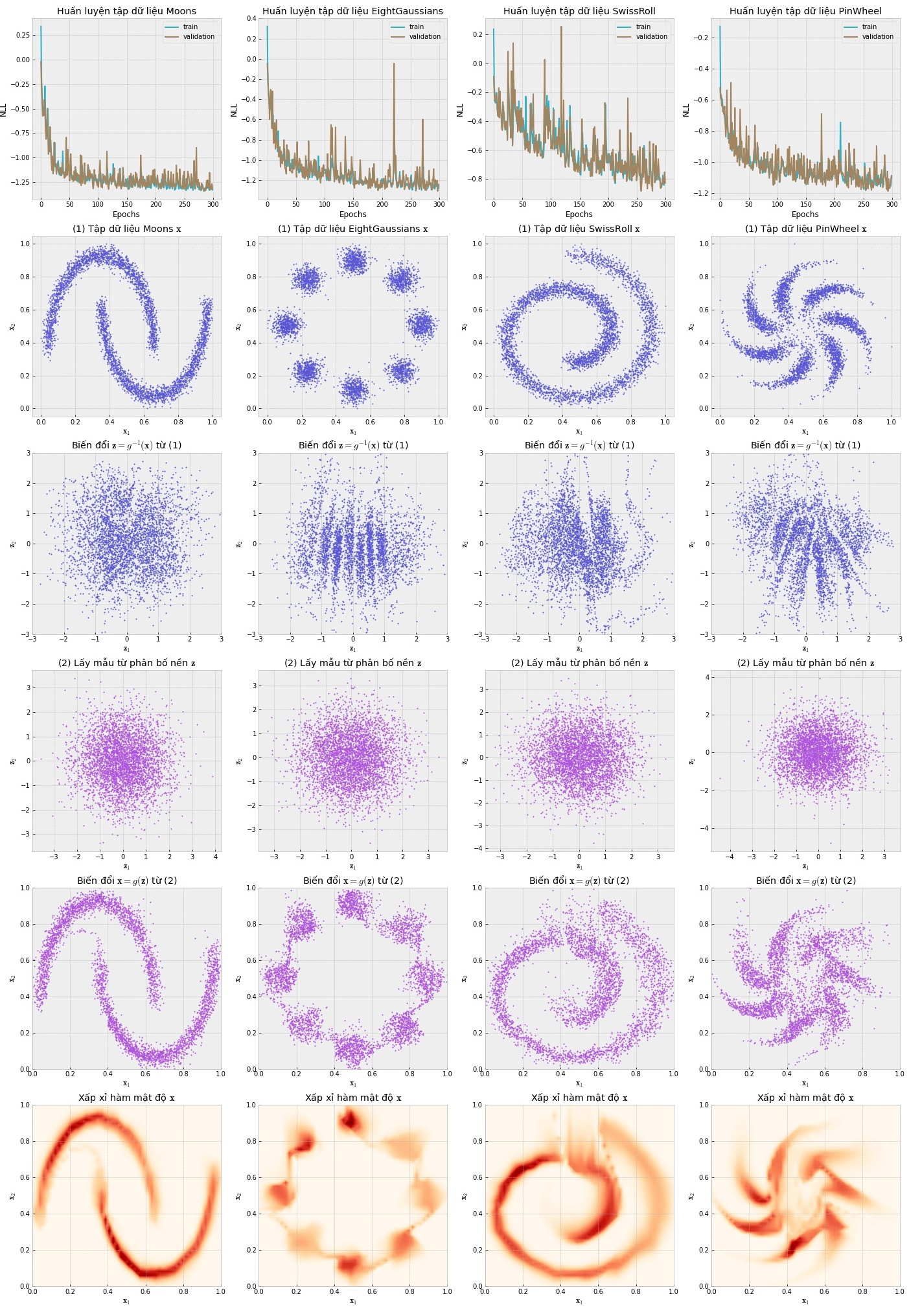
Giờ thì mô tả xem từng lớp trong mô hình mạng biến đổi các điểm dữ liệu như thế nào nhé!

5. Ứng dụng
Tưởng tượng là nơi mọi ứng dụng bắt đầu… Hãy tưởng tượng rằng phân bố phức tạp kia nay là một đoạn âm thanh, một bức ảnh, một vần thơ, một thị trường… và hãy nhớ rằng… sự sáng tạo của bạn là then chốt của ứng dụng… vì quyền làm gì với nằm trong lòng bàn tay của bạn… xào nấu nướng ra bất kì ứng dụng nào hữu ích… tùy theo trí tưởng tượng đưa ta đi đâu.
Một số mô hình Normalizing Flows thành công có thể tham khảo:
Glow (OpenAI): dựa trên kiến trúc RealNVP (Yeahhhh, mới viết xong haha), Glow của OpenAI có nhiều ứng dụng thú vị có thể vọc vạch tại: https://openai.com/blog/glow/. Ngoài ra một số Notebook hay có thể đọc ở https://github.com/tensorchiefs/dl_book/blob/master/chapter_06/nb_ch06_05.ipynb
Parallel WaveNet: một mô hình âm thanh phát triển ý tưởng từ WaveNet và Inverse Autoregressive Flows. Xem tại: https://arxiv.org/abs/1711.10433.
Phần Notebook của RealNVP ThetaLog bạn có thể tải về ở đây: repo.
Hy vọng bạn đọc sẽ có những giây phút thú vị với Normalizing Flows!
ThetaLog - Nhật ký Theta
Tham khảo
- CS236, taught by Stefano Ermon and Aditya Grover, and have been written by Aditya Grover. Normalizing flow models. https://deepgenerativemodels.github.io/notes/flow/
- Lilian Weng. Flow-based Deep Generative Models. https://lilianweng.github.io/posts/2018-10-13-flow-models/
- Oliver Duerr. Probabilistic Deep Learning: With Python, Keras and TensorFlow Probability. https://github.com/tensorchiefs/dl_book
- Ivan Kobyzev, Simon J.D. Prince, Marcus A. Brubaker. Normalizing Flows: An Introduction and Review of Current Methods. https://arxiv.org/abs/1908.09257
- Ari Seff. What are Normalizing Flows?. https://www.youtube.com/watch?v=i7LjDvsLWCg
- Ivan Kobyzev, Simon J.D. Prince, Marcus A. Brubaker. Normalizing Flows: An Introduction and Review of Current Methods. https://arxiv.org/abs/1908.09257
- Eric Jang. Normalizing Flows Tutorial, Part 1: Distributions and Determinants. https://blog.evjang.com/2018/01/nf1.html
- Laurent Dinh, Jascha Sohl-Dickstein, Samy Bengio. Density estimation using Real NVP. https://arxiv.org/abs/1605.08803
- Affine Coupling. https://paperswithcode.com/method/affine-coupling
- Kevin Webster. Coursera. Probabilistic Deep Learning with TensorFlow 2. https://www.coursera.org/lecture/probabilistic-deep-learning-with-tensorflow2/coding-tutorial-normalising-flows-Fro8i