

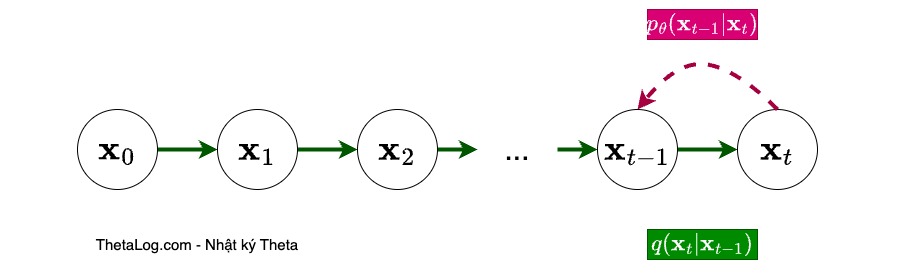
Denoise diffusion probabilistic models
Nội dung bài viết
Diffusion models là nhóm mô hình sinh dựa trên ý tưởng quá trình ngẫu nhiên khuyếch tán của vật lí. Thả giọt mực vào một cốc nước, các phân tử sẽ lan tỏa, cốc nước ban đầu sớm nhộm màu đồng đều bởi các phân tử có mặt khắp nơi. Nghệ thuật là đây, nếu cầm trong tay một cốc màu đã tan. Liệu có cách nào quay ngược thời gian lại phân bố trạng thái ban đầu của một trạng thái giọt mực ban đầu.

Nếu phân bố xác suất có thể ví von như bản đồ niềm tin đặc tả bởi các con số, liệu ta có thể xây dựng một chuổi phác thảo các bản đồ được sắp xếp trình tự một cách hợp lí để quay ngược thời gian từ thời điểm kết thúc đến thời điểm bắt đầu?
Một trong những hướng tiếp cận mô hình sinh (generative model) là định nghĩa một quá trình ngẫu nhiên mà bạn có thể hiểu quá trình thuận nghịch của nó. Dữ liệu thực tế (ví dụ: ảnh số) có phân bố rất phức tạp, khó lòng có thể mô hình hóa lấy mẫu trực tiếp, thay vì vậy ta có thể chuyển nhiều bài toán về dạng đơn giản hơn, bằng cách chuyển phân bố phức tạp thành phân bố đơn giản và lấy mẫu trên quá trình dịch ngược.
1. Lối mẫu ngẫu nhiên, đi dể khó về
Mới hôm nao, kí ức ngày tựu trường trong veo, vậy mà giờ đây chỉ còn là bức tranh nhạt nhòa. Mỗi ngày lại quên đi một chút ít, bức tranh ngày ấy mờ dần theo tháng năm. Gắng nhớ mãi cũng không thể nào nhớ lại được “một mạch” thời điểm ấy bắt đầu như thế nào.
Nếu là một kẻ du hành thời gian, liệu ta có thể xâu chuỗi các mắc xích thời gian. Xây dựng quá trình tiến khiến tất cả sẽ tan biến chỉ còn dĩ vãng. Xây dựng quá trình lùi cứ đi từng bước một và tưởng tượng ngày ấy thế nào. Hợp lí hóa cả cả hai quá trình, liệu ta có thể quay ngược lại nơi bắt đầu?
Lấy ý tưởng tương tự, ta sẽ định nghĩa một quá trình tăng nhiễu dần đến khi phân bố gốc trở thành phân bố chuẩn tắc nhiều chiều. Tại mỗi bước đi lùi, ta sẽ ước tính tham số phân bố dịch ngược với T bước nhảy thời gian dài đăng đẳng. Và hợp lí hóa quá trình trên bởi phân bố hội của quá trình tiến & lùi qua ELBO.
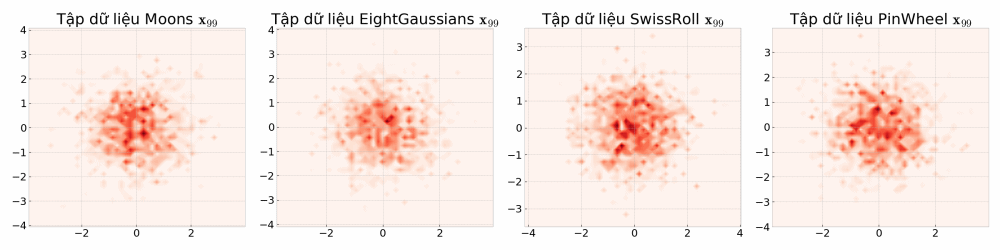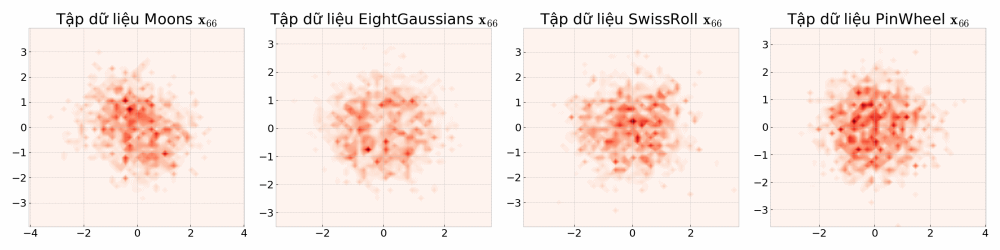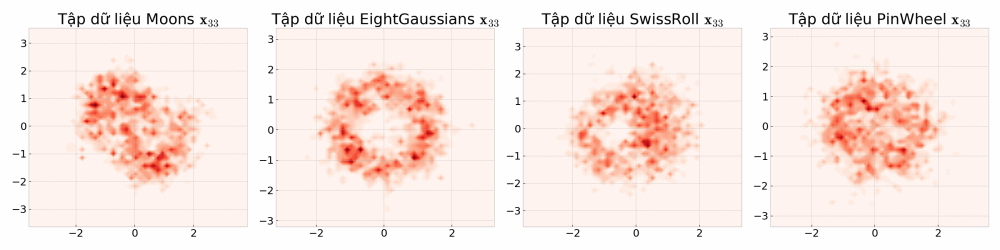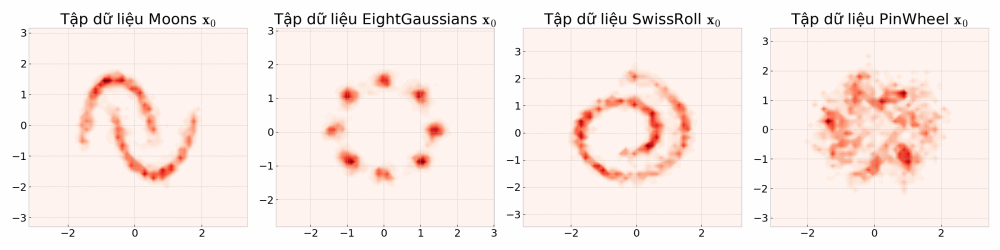
Mô phỏng thử các lối mẫu ngẫu nhiên (sample path của stochastic process) của quá trình khuyếch tán, bạn sẽ thấy có vô vàn kết quả để đến một vị trí đích. Nếu chọn một vị trí đích \( \mathbf{x}_t \) (điểm dữ liệu \( \mathbf{x} \) tại thời điểm \( t \) ) một câu hỏi được đặt ra, nếu tất cả các điểm đều có thể định lượng cơ hội xảy ra bằng một con số, cơ hội sẽ được phân bố như thế nào, nơi nào nhiều hơn, nơi nào ít hơn?
Một cách đơn giản nhất để đi ngược thời gian là sẽ di chuyển ngược hàm mật độ khi biết vị trí đang đứng hiện tại ở \( t \), hay nói một cách khác cố gắng mô hình hóa phân bố \( p(\mathbf{x}_{t - 1} | \mathbf{x}_t) \) được tham số hóa.
Nhưng nếu mô phỏng đủ nhiều, bạn sẽ thấy phân bố này tương đối phức tạp, và cũng chẳng có thông tin nào về nó cả… đấy là cái khó khi… đó là nếu, đó là mơ, quá trình nghe vẫn rất kiêu, vẫn rất khó để làm điều như vậy. Nhưng hãy cùng nhau làm mọi thứ đơn giản hơn nào!
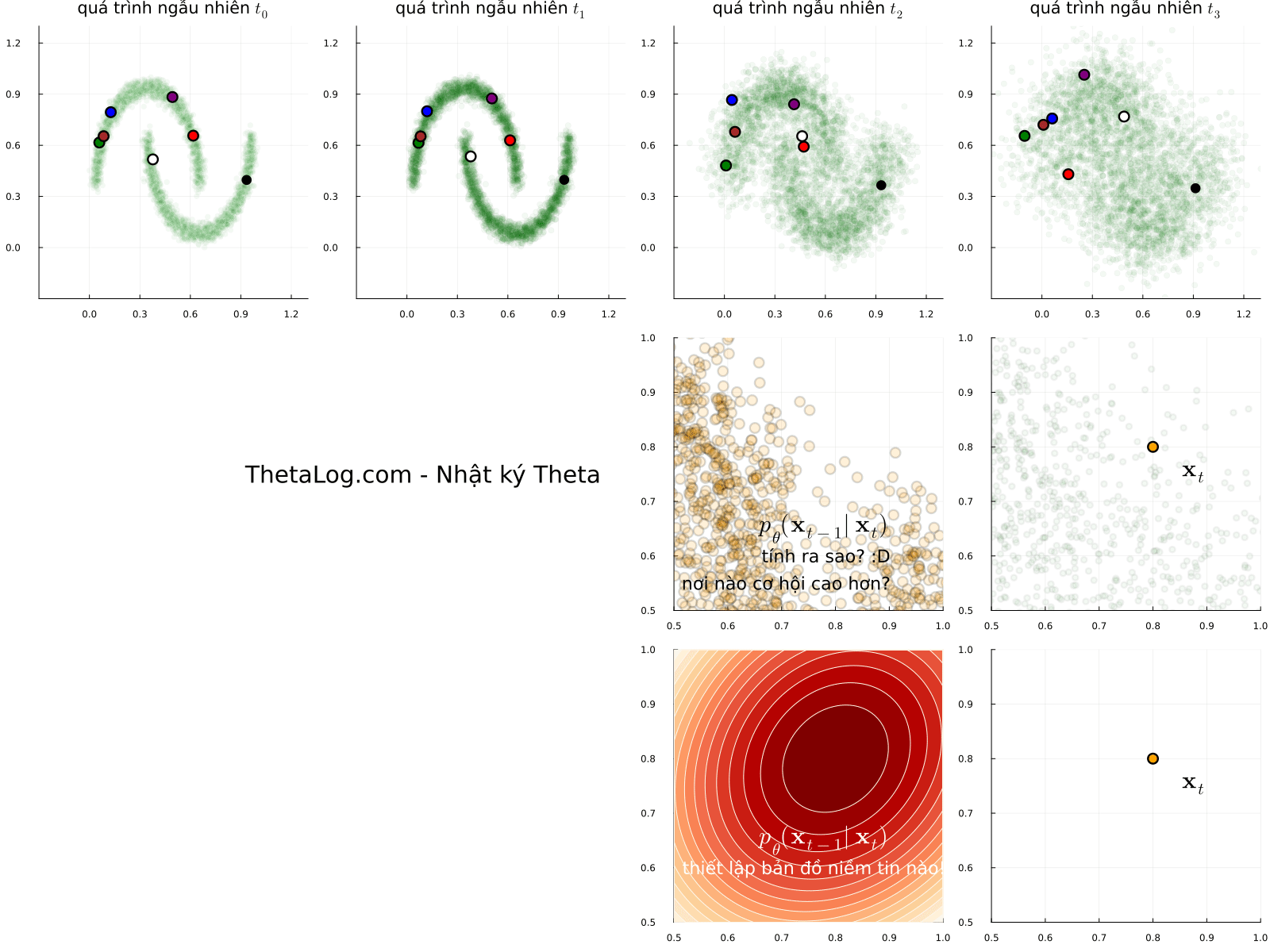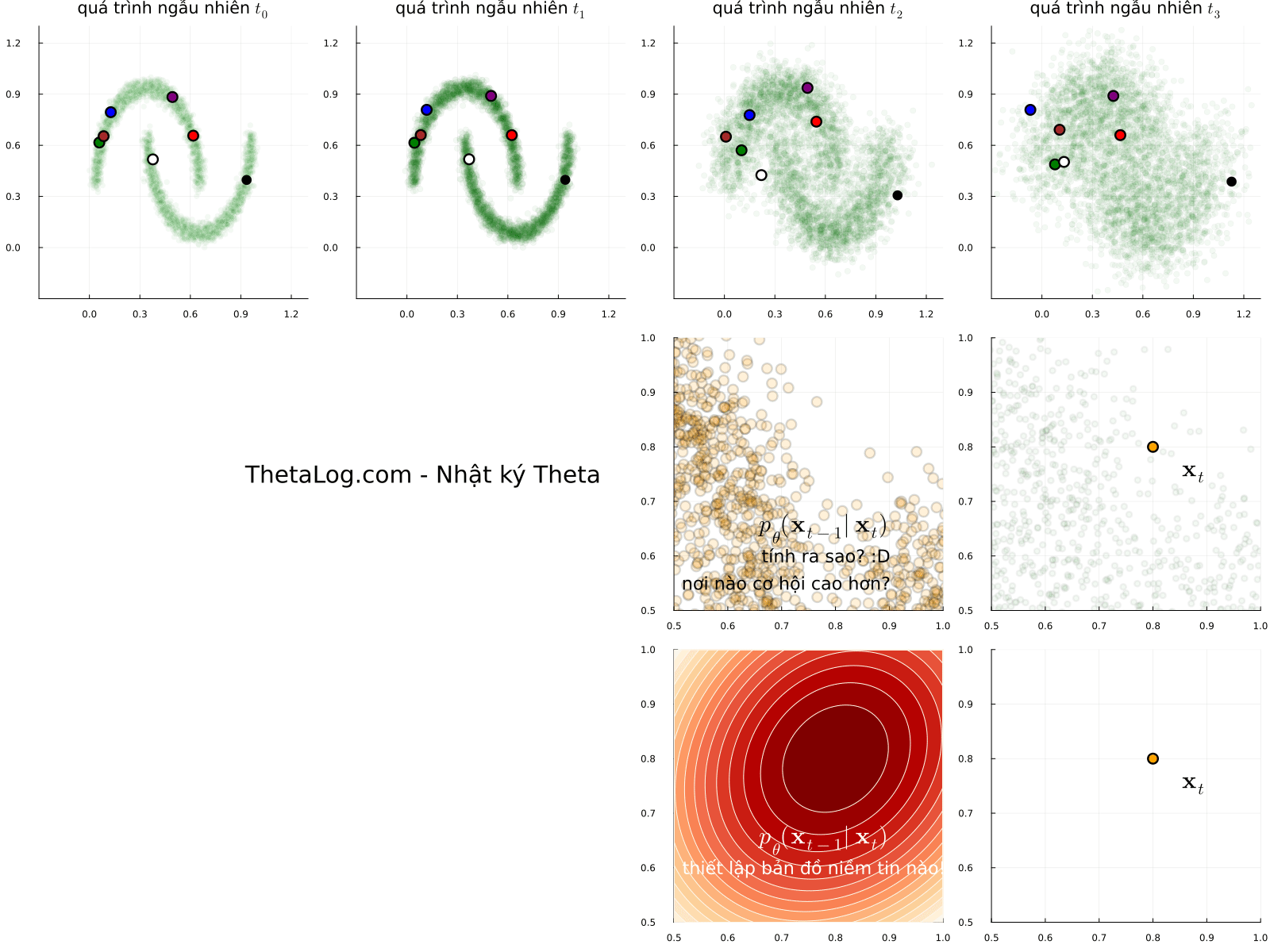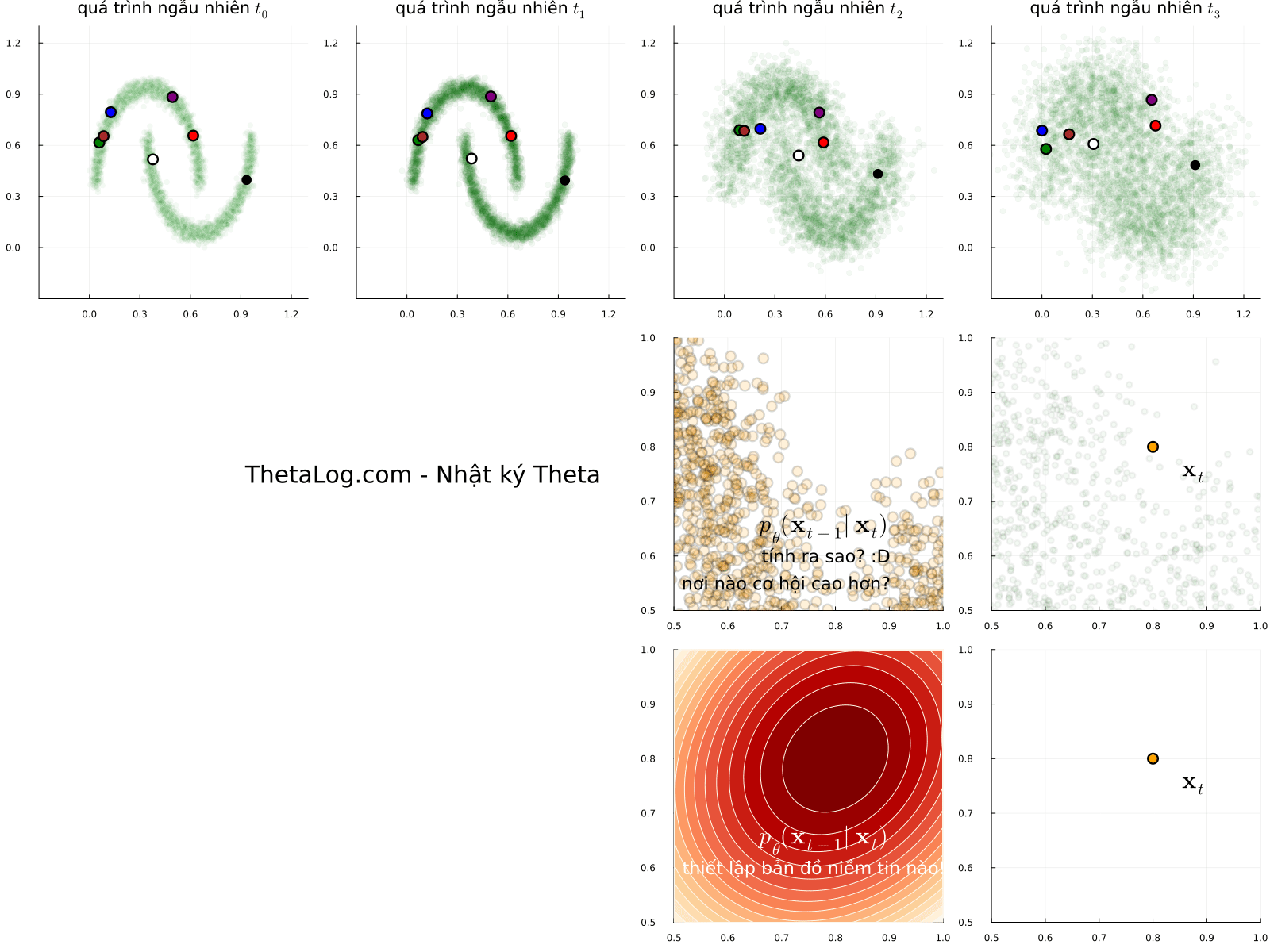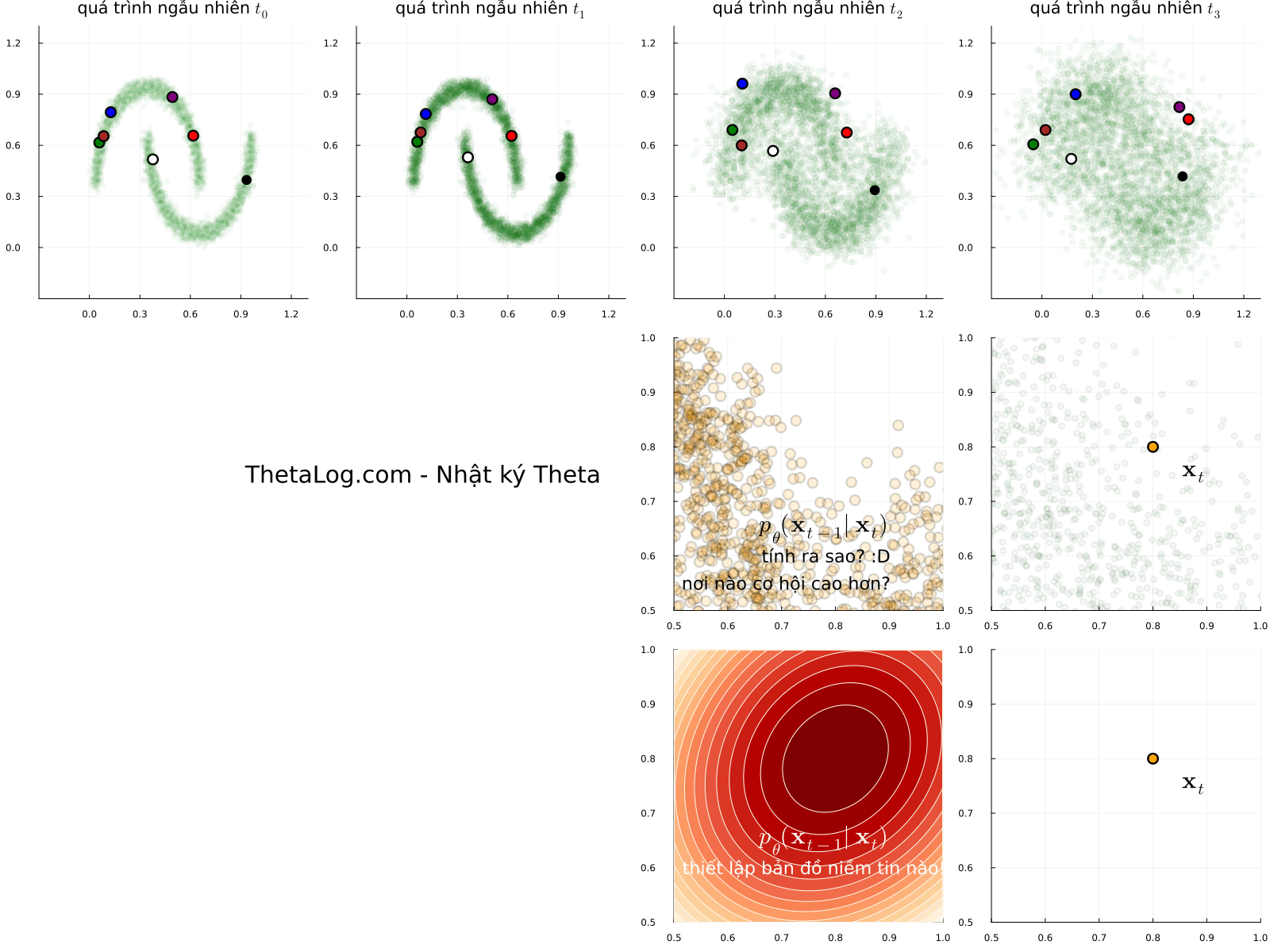
Giải thích hình vẽ:
- Mỗi khung ảnh chuyển động là một lối mẫu ngẫu nhiên có thể xảy ra (đùa tí cho vui: hãy tưởng tượng bạn là Dr Strange và thấy được tất cả các kết quả của các thế giới khác nhau). Nếu để ý, các điểm được đánh dấu có thể di chuyển bất kì đâu.
- Nếu như ta ở điểm màu cam \( \mathbf{x}_t \), vì các điểm có thể di chuyển bất kì đâu, để đi lùi quá khứ ta có thể xây dựng bản đồ niềm tin a.k.a phân bố xác suất dịch ngược \( p_\theta(\mathbf{x}_{t - 1} | \mathbf{x}_t) \) , hmmm nhưng mà xây dựng như thế nào nhỉ? Một câu hỏi thú vị là nơi một hành trình bắt đầu… đi thôi nào…
2. Denoise Diffusion Probabilistic Models:
Sỡ dĩ gọi là Denoise Diffusion Probabilistic Models là vì:
- Quá trình tiến (Forward Process) ý tưởng cảm hứng từ quá trình khuyếch tán (diffusion)
- Quá trình lùi (Reverse Process) tại đây ta chỉ có điểm dữ liệu trông giống như nhiễu :D ví von quá trình đi dịch chuyển lịch sử giống như việc khữ nhiễu bức ảnh cũ kĩ đến khi dữ liệu trở về nguyên bản.
Trong bài viết này dùng kí hiệu \( \mathcal{N}(.) \) để kí hiệu cho phân bố chuẩn nhiều chiều.
Việc lựa chọn phân bố xác suất trong mô hình phụ thuộc nhiều tiêu chí: phù hợp mô tả quá trình xác suất, dể tính toán. Phân bố chuẩn có nhiều tính chất đẹp & tiện lợi cho việc tính toán nên được sử dụng nhiều trong bài toán này.
2.1 Quá trình tiến (Forward Process)
Quá trình tiến tại mỗi bước nhảy thời gian đơn giản là dần dần cộng thêm nhiễu vào. Hay nói cách khác:
Nếu chọn nhiễu được sinh ra từ phân bố chuẩn \( \xi_{t-1} \sim \mathcal{N} \left( \color{green} \mu_{ \xi_{ t-1 } } \color{black}, \color{blue} \Sigma_{\xi_{t-1}} \right) \) . Tinh gọn công thức lại thành một phân bố duy nhất, có thể viết:
Ký hiệu \( q \) là hàm mật độ của quá trình tiến, ta có:
Trong bài báo Denoising Diffusion Probabilistic Models hàm mật độ được chọn:
Với:
- \( t \) là bước nhảy thời gian từ \( 1 \) đến \( T \).
- \( \beta_{t} \) là phương sai lịch trình (schedule variance).
\( \beta_{t} \) và \( T \) được gán cứng. Không thay đổi trong quá trình huấn luyện mô hình.
Để hiểu lựa chọn trên, chúng ta sẽ cùng nhau phân tích quá trình này.
Dẫu chúng ta học về quá trình ngẫu nhiên, ấy vậy hầu như không có sự chọn lựa ngẫu nhiên trong lúc xây dựng mô hình :D mọi thứ đã được toan tính kỹ lưỡng cho một tương lai xa. Công thức trên nếu được thiết lập một cách đúng đắn, tại cuối quá trình ta sẽ trở về phân bố chuẩn tắc nhiều chiều.
Khi đó phân bộ hội (joint distribution) của một lối mẫu ngẫu nhiên cùng nhau xuất hiện \( \mathbf{x}_1, \mathbf{x}_2,… \mathbf{x}_t \) được tính như sau:
Một tính chất đáng chú ý của quá trình tiến, vì chọn nhiễu có phân bố chuẩn, ta có thể tùy tiện lấy mẫu tại một bước nhảy bất kì với:
Với:
- \( \alpha_t = 1 - \beta_t \)
- \( \bar{\alpha_t} = \prod_{s=1}^{t} \alpha_s \)
Bởi vì chúng ta muốn cuối quá trình là phân bố chuẩn tắc nhiều chiều:
$$ q(\mathbf{x}_T | \mathbf{x}_0 ) \approx \mathcal{N} (0, \mathbb{I}) $$
Hay nói cách khác
$$ \bar{\alpha}_T \approx 0 $$
Việc chọn phương sai lịch trình \( \beta \) và \( T \) bước nhảy là không khó để thỏa mãn điều kiện trên.
2.2 Quá trình lùi (Reverse Process)
Trở về câu hỏi ban đầu, liệu ta có thể mô hình hóa \( p(\mathbf{x}_{t-1} | \mathbf{x}_t) \). Như thường lệ… cái hay cái đẹp sẽ không bao giờ đến một cách dể dàng…
Nếu mô phỏng đủ nhiều, bạn sẽ thấy phân bố này quá phức tạp để có thể mô hình hóa. Mà nếu, nếu có mô hình hóa được, thì cũng rất khó tối ưu, thật đấy thử đi.
Một lời giải hay không phải là một lời giải chính xác tuyệt đối, mà một lời giải đủ khéo léo và tinh vi…
Gọi \( p(\mathbf{x}_{t-1} | \mathbf{x}_t) \) là hàm mật độ lùi có phân bố chuẩn nhiều chiều chưa biết tham số phân bố:
Tuy vậy, tham số của phân bố vẫn chưa rõ. Nếu để ý, ta có thể thấy phân bố của mỗi điểm phụ thuộc vào vị trí \( \mathbf{x}_t \) và bước nhảy thời gian \( t \).
…hmmm, với sức mạnh tính toán của các mô hình học sâu, chúng ta hoàn toàn có thể xấp xĩ các tham số này! Dường như đây là mảnh ghép quan trọng còn thiếu trong bài toán này.
Phân bố chuẩn nhiều chiều có 2 tham số cần tìm là trung bình và ma trận hiệp phương sai. Tuy vậy nếu càng ít tham số phải tính thì bài toán sẽ càng dể hơn nhiều lần. [Ho et al., 2020] cho thấy chúng ta có thể chọn ma trận hiệp phương sai là \( \beta_t \).
Gọi \( \mu_\theta (\mathbf{x}_t, t) \) là trung bình được xấp xĩ của mạng học sâu mà ta sẽ xây dựng. Ta có:
Lúc này phân bố hội qúa trình lùi có thể viết lại:
2.3 Huấn luyện mô hình
Trước hết, khi vào bài toán này ta chỉ có điểm dữ liệu tại thời gian ban đầu \( \mathbf{x}_0 \) (biết trước), mọi trình tự ngẫu nhiên phía sau \( \mathbf{x}_{1:T} \) được sinh ra từ phân bố quá trình tiến \( q(. | \mathbf{x}_0) \). Như anh chàng thám tử trong thế giới ngẫu nhiên, ta thử dùng bất đẳng thức ELBO (Evidence lower bound \( \color{black} \ln p( \color{blue} a \color{black} ) \ge \mathbb{E}_{b \sim q(. | a )} \left[ \ln \frac{ p( \color{blue} a \color{black} , \color{red} b \color{black} ) }{q( \color{red} b \color{black} | \color{blue} a \color{black} )} \right] \) ), ta có:
Vì sao không tối ưu trực tiếp loglikelihood của \( p_\theta (\mathbf{x}_0) \) ? Đơn giản là vì nó khó lấy trong bài toán này.
Vì ta muốn áp dụng cho toàn bộ tập dữ liệu, lấy kì vọng vế trái và phải ta có (lưu ý: kỳ vọng của kỳ vọng viết đơn giản thành kỳ vọng), ta sẽ tối ưu vế phải bài toán này, vế phải càng nhỏ thì vế trái càng nhỏ:
Liệu bạn có cảm nhận được điều gì không hửm thám tử SherLog Holmes? Vế phải tử thức là phân bố hội quá trình lùi, mẫu thức là phân bố hội quá trình tiến? Liệu công thức ý ẩn ý gì chăng?
Nếu tiếp tục đơn giản hóa công thức, bạn sẽ nhận ra vế phải là tổng của KL-divergence của từng bước nhảy thời gian quá trình tiến và quá trình lùi, và đằng sau đó là công thức tường minh đẹp sau lớp mặt nạ ngụy trang. Nào hãy cùng vạch trần… công thức…
Ta có thể phân tích vế phải thành:
Ta có thể áp dụng công thức Bayes:
Nên ta có (tiếp tục đoạn đang viết dỡ):
Mà vì \( \ln \) của phép nhân có thể phân tích ra tổng, của phép chia có thể phân ra hiệu, và ta lại có:
Lúc này ta có thể viết tiếp:
Sỡ dĩ ở đây chúng ta có thể phân tích ra thành KL Divergence bởi vì bản chất KL Divergence là kỳ vọng lograrít giữa hai phân bố.
Nhận thấy:
- \( L_T \): không có tham số tối ưu. Có thể lược giản.
- \( L_0 \): bình thường công thức này trong ELBO chúng ta có thể xấp xĩ bằng cách lấy mẫu ngẫu nhiên Monte Carlo. Tuy vậy nhóm tác giả đã gộp vào công thức tính của \( L_{t-1}\)
- \( L_{t-1}\): có công thức đẹp : ) vì đó là KL-divergence giữa hai phân bố chuẩn.
Do KL Divergence đang lấy là của hai phân bố chuẩn nhiều chiều, ta có công thức tường minh:
Với \( C \) là hằng số. Do đó ta có thể loại khỏi công thức tối ưu.
Nhưng than ôi, 30 chưa phải là tết, cái kết chưa đến. Nếu là một người làm tối ưu hóa, công thức trên vẫn khó tối ưu. Mặc dù bạn hoàn toàn có thể lấy mẫu \( \mathbf{x}_t \) một cách đơn giản, tuy vậy thách thức lớn nhất là làm sao cho mô hình khả vi tối ưu tham số được với vectơ gradient.
Ta sẽ dùng mẹo tái tham số hóa (reparametrization trick, bạn đọc quan tâm có thể đọc thêm bài viết thú vị [6]). Vì phân bố chuẩn thuộc họ Location–scale family ta có thể viết:
Như đã nói ở quá trình tiến, bởi vì điều thú vị trong bài toán này cho phép ta lấy mẫu tùy tiện, kỳ vọng của quá trình tiến có thể viết \( \tilde{\mu_{t} } (\mathbf{x}_t, \mathbf{x}_0) = \frac{\sqrt{\bar{\alpha}_{t-1}} \beta_t }{1 - \bar{\alpha}_{t}} \mathbf{x}_0 + \frac{ \sqrt{\alpha_t} (1 - \bar{\alpha}_{t-1}) }{1 - \bar{\alpha}_{t}} \mathbf{x}_{t} \) .
Lúc này ta có thể viết \( L_t \) lại thành:
Bởi vì \( \mathbf{x}_t \) đã có, hơn nữa nếu nhìn vào công thức trên thì mạng \( \mu_\theta \) phải dự đoán \( \frac{1}{ \sqrt{\alpha_t}} \left( \mathbf{x}_t (\mathbf{x}_0, \epsilon ) - \frac{\beta_t}{\sqrt{1- \bar{\alpha}_t}} \epsilon \right) \) do đó ta có thể “cố tình” chọn tham số hóa như sau:
Với \(\epsilon_\theta(\mathbf{x_t, t}) \) là hàm xấp xĩ \( \mathbf{x}_t \) khi biết \( \mathbf{x}_t \). Khi đó việc lấy mẫu \( \mathbf{x}_{t-1} \sim p_{\theta} (\mathbf{x}_{t-1} | \mathbf{x}_{t} ) \) được tính toán:
Lúc này, nếu thế vào công thức cuối cùng ta có:
Tuy nhiên, nhóm tác giả DDPM đề xuất một công thức tinh gọn hơn:
Với công thức trên \( t=1 \) ứng với \( L_0 \) (trong bài viết này không chứng minh, bạn có thể đọc thêm tài liệu [1] phần 3.3), với \( t > 1\) tương ứng \( L_{t-1} \) không trọng số.
2.4 Mã giả huấn luyện mô hình
Trong mã nguồn bên dưới bạn có thể tìm đến phần comment tương ứng trong source code bằng cách tìm:
[Pseudocode T3][Pseudocode T4][Pseudocode T5][Pseudocode T7]
T2 | Repeat {
T3 | \( \mathbf{x}_0 \sim q(\mathbf{x}_0) \)
T4 | \( t \sim \text{Uniform}(\{1,..., T \}) \)
T5 | \(\epsilon \sim \mathcal{N}(0, \mathbb{I}) \)
T6 | Lấy vectơ gradient và cập nhật tham số
T7 | \(\nabla_\theta \left\lVert \epsilon - \epsilon_{\theta} ( \sqrt{ \bar{\alpha}_t } \mathbf{x}_0 + \sqrt{ 1 - \bar{ \alpha}_t } \epsilon , t) \right\rVert^2 \)
T8 | } Until (hội tụ)
T9 | END
2.4 Mã giả lấy mẫu
Trong mã nguồn bên dưới bạn có thể tìm đến phần comment tương ứng trong source code bằng cách tìm:
[Pseudocode S2][Pseudocode S3][Pseudocode S4][Pseudocode S5]
S2 | \( \mathbf{x}_T \sim \mathcal{N}(0, \mathbb{I}) \)
S3 | For \(t=T,...,1\) do {
S4 | \(\mathbf{z} \sim \mathcal{N}(0, \mathbb{I} ) \text{ if } t > 1, \text{ else } \mathbf{z} = 0 \)
S5 | \(\mathbf{x}_{t-1} = \frac{1}{ \sqrt{\alpha_t}} \left( \mathbf{x}_t - \frac{\beta_t}{\sqrt{1- \bar{\alpha}_t}} \epsilon_\theta(\mathbf{x_t, t}) \right) + \sigma_t \mathbf{z} \)
S6 | } End For
S7 | RETURN \(\mathbf{x}_0 \)
3. Cài đặt DDPM
Phần mã nguồn đưới đây được cài đặt với PyTorch cho dữ liệu giả lập trong không gian 2 chiều để dể hình dung về mặt lý thuyết. Bạn đọc quan tâm với dữ liệu ảnh có thể đọc thêm ở phần 4.
import tqdm
import numpy as np
import torch
from torch import nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from sklearn.datasets import make_moons, make_swiss_roll
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KernelDensity
from sklearn.preprocessing import StandardScaler
import matplotlib.pyplot as plt
plt.style.use("bmh")
plt.rcParams.update({'font.size': 18})
device = 'cpu'
dtype = torch.float32
np_dtype = np.float32
n_steps = 100
n_epochs = 300
Set seed nào
def set_seed_for_dreams(just_another_random_dream):
"""
For detail implementation
Watch "Inception"
https://open.spotify.com/track/6ZFbXIJkuI1dVNWvzJzown
"""
np.random.seed(just_another_random_dream)
torch.manual_seed(just_another_random_dream)
print(f"""
City of {just_another_random_dream} Star{
's' if just_another_random_dream!= 1 else ''}
""")
set_seed_for_dreams(12)
def make_synthetic_data(name_dataset, n_samples=4048, noise=0.05, dtype=np_dtype):
"""Tạo dữ liệu nhân tạo x
"""
scaler = StandardScaler()
if name_dataset == "Moons":
x, _ = make_moons(n_samples, noise=noise)
elif name_dataset == "EightGaussians":
sq_2 = np.sqrt(2)
c_s = 5.
centers = [(1, 0), (-1, 0), (0, 1), (0, -1),
(1. / sq_2, 1. / sq_2),
(1. / sq_2, -1. / sq_2),
(-1. / sq_2, 1. / sq_2),
(-1. / sq_2, -1. / sq_2)]
centers = [(c_s * x_1, c_s * x_2) for x_1, x_2 in centers]
x = []
for i in range(n_samples):
p = np.random.randn(2) * 0.5
idx = np.random.randint(8)
center = centers[idx]
p[0] += center[0]
p[1] += center[1]
x.append(p)
x = np.array(x)
elif name_dataset == "SwissRoll":
x = make_swiss_roll(n_samples=n_samples, noise=0.7)[0][:, [0, 2]]
elif name_dataset == "PinWheel":
std_rad = 0.3
tang_std = 0.1
n_wheel = 7
n_p_wheel = n_samples // n_wheel
r = 0.25
rads = np.linspace(0, 2 * np.pi, n_wheel, endpoint=False)
feats = np.random.randn(n_wheel * n_p_wheel, 2) * np.array([std_rad, tang_std])
feats[:, 0] += 1.
labels = np.repeat(np.arange(n_wheel), n_p_wheel)
theta = rads[labels] + r * np.exp(feats[:, 0])
rot_mat = np.stack([np.cos(theta), -np.sin(theta), np.sin(theta), np.cos(theta)])
rot_mat = np.reshape(rot_mat.T, (-1, 2, 2))
x = np.random.permutation(np.einsum("ti,tij->tj", feats, rot_mat))
x = scaler.fit_transform(x)
x = x.astype(dtype)
return x
names_dataset = ["Moons", "EightGaussians", "SwissRoll", "PinWheel"]
datasets = {name: make_synthetic_data(name) for name in names_dataset}
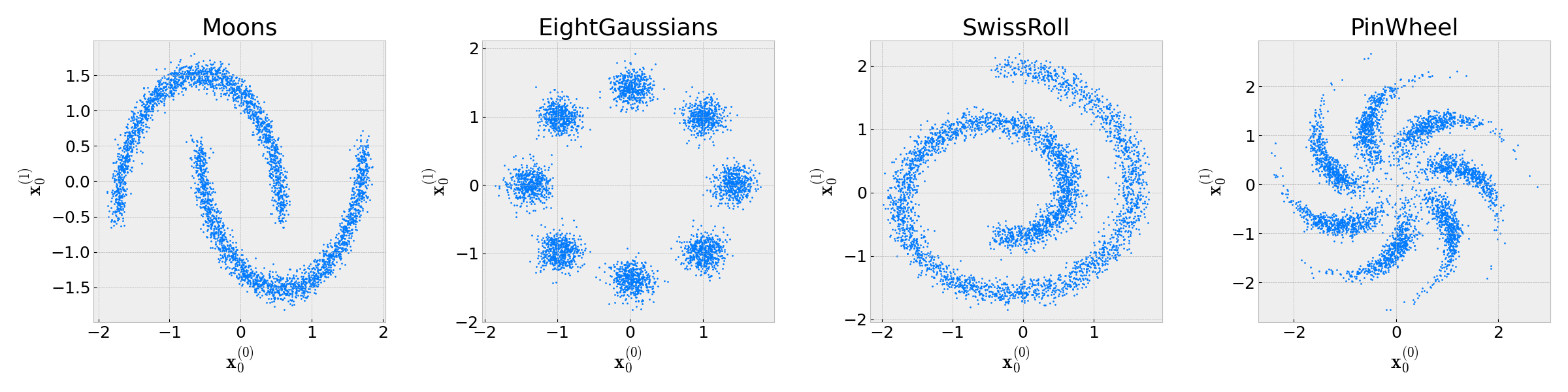
Vẽ vời thử xem dữ liệu ra làm sao nào:
fig, axes = plt.subplots(1, len(names_dataset), figsize=(6 * len(names_dataset), 6),
gridspec_kw={'width_ratios': [1] * len(names_dataset)})
for i in range(len(names_dataset)):
name = names_dataset[i]
x = datasets[name]
if len(datasets) != 1:
axes[i].scatter(x[:, 0], x[:, 1], c="#007aff", s=2)
axes[i].set(title=f"{name}",
xlabel="$\mathbf{x}_0^{(0)}$", ylabel="$\mathbf{x}_0^{(1)}$")
else:
axes.scatter(x[:, 0], x[:, 1], c="#007aff", s=2)
axes.set(title=f"{name}",
xlabel="$\mathbf{x}_0^{(0)}$", ylabel="$\mathbf{x}_0^{(1)}$")
plt.tight_layout()
plt.show()
class EpsilonThetaNetwork(nn.Module):
"""
Mạng xấp xĩ epsilon
phần này thiết kế tùy tập dữ liệu
(do it yourself :D)
"""
def __init__(self, n_steps, x_flatten_shape=2,
n_embeds=50, device='cpu', dtype=torch.float64):
"""
Hảm khởi tạo
:param n_steps: số lượng bước nhảy T = n_steps
:param x_flatten_shape: số chiều của x0
:param n_embeds: dành cho layer embed của t
:param device: thiết bị sử dụng
:param dtype: kiểu số thực float32 hay float64
"""
super(EpsilonThetaNetwork, self).__init__()
self.n_steps = n_steps
self.n_embeds = n_embeds
self.device = device
self.embeds = nn.Embedding(n_steps, n_embeds,
device=device, dtype=dtype)
self.hidden1 = nn.Sequential(
nn.BatchNorm1d(2 + n_embeds, device=device, dtype=dtype),
nn.Linear(2 + n_embeds, 128, device=device, dtype=dtype),
nn.LeakyReLU(0.1),
nn.BatchNorm1d(128, device=device, dtype=dtype),
nn.Linear(128, 64, device=device, dtype=dtype),
nn.LeakyReLU(0.1),
nn.BatchNorm1d(64, device=device, dtype=dtype),
nn.Linear(64, 32, device=device, dtype=dtype),
nn.LeakyReLU(0.1),
nn.BatchNorm1d(32, device=device, dtype=dtype),
nn.Linear(32, 16, device=device, dtype=dtype),
nn.Tanh(),
nn.BatchNorm1d(16, device=device, dtype=dtype),
nn.LeakyReLU(0.1),
nn.Linear(16, x_flatten_shape, device=device, dtype=dtype),
)
self.concat_layer = nn.Linear(
x_flatten_shape * 2, x_flatten_shape, device=device, dtype=dtype)
def forward(self, xt, t):
"""
Epsilon Theta
:param xt:
:param t:
:return:
"""
t_embed = self.embeds(t.view(-1, 1))
v1 = torch.hstack([xt, t_embed.view(xt.size()[0], self.n_embeds)])
h1 = self.hidden1(v1)
v2 = torch.hstack([h1, xt])
epsilon_theta = self.concat_layer(v2)
return epsilon_theta
class DenoisingDiffusionProbabilisticModel(nn.Module):
def __init__(self, epsilon_model, n_steps, device):
super(DenoisingDiffusionProbabilisticModel, self).__init__()
self.epsilon_model = epsilon_model
self.beta = torch.linspace(0.0001, 0.02, n_steps).to(device)
self.alpha = 1. - self.beta
self.alpha_bar = torch.cumprod(self.alpha, dim=0)
self.sigma2 = self.beta
self.T = n_steps - 1
self.n_steps = n_steps
def sample_q(self, x0, t, epsilon=None):
"""
Công thức lấy mẫu xt ~ q(xt | x0)
:param x0:
:param t:
:param epsilon:
:return: xt
"""
if epsilon is None:
epsilon = torch.randn_like(x0)
alpha_bar = self.alpha_bar.gather(-1, t).view(-1, 1)
mu = torch.sqrt(alpha_bar) * x0
sigma = torch.sqrt(1 - self.alpha_bar.gather(-1, t).view(-1, 1))
return mu + sigma * epsilon
def sample_p(self, xt, t):
"""
Công thức lấy mẫu xt ~ p(x_{t-1} | x_{t})
:param xt:
:param t:
:return: x_{t-1}
"""
epsilon_theta = self.epsilon_model(xt, t)
alpha_bar = self.alpha_bar.gather(-1, t).view(-1, 1)
alpha = self.alpha.gather(-1, t).view(-1, 1)
coef = (1 - alpha) / torch.sqrt(1 - alpha_bar)
mu = 1 / torch.sqrt(alpha) * (xt - coef * epsilon_theta)
sigma = torch.sqrt(self.sigma2.gather(-1, t).view(-1, 1))
if t.sum() == 0: # [Pseudocode S4]
z = torch.zeros_like(sigma, device=xt.device)
else:
z = torch.randn(xt.shape, device=xt.device)
return mu + sigma * z # [Pseudocode S5]
def forward_process(self, x0):
t = (self.n_steps-1) * torch.ones(size=(x0.shape[0],), dtype=torch.long)
xt = self.sample_q(torch.tensor(x0), t)
return xt
def reverse_process(self, data_size):
x_t = torch.randn(size=(data_size, 2)) # [Pseudocode S2]
for i in reversed(range(self.n_steps)): # [Pseudocode S3]
t = i * torch.ones(size=(data_size,), dtype=torch.long)
x_t = self.sample_p(x_t, t)
return x_t
def pdf_reverse_samples(self, x, bandwidth=0.05):
density_data = self.reverse_process(10_000)
kde = KernelDensity(kernel='gaussian', bandwidth=bandwidth)
kde.fit(density_data.detach().numpy())
return kde.score_samples(x)
def loss_func(x0, model: DenoisingDiffusionProbabilisticModel):
# [Pseudocode T4] lấy ngẫu nhiên bước nhảy thời gian
t = torch.randint(0, model.n_steps - 1, (x0.shape[0],), device=x0.device, dtype=torch.long)
# [Pseudocode T5] lấy ngẫu nhiên epsilon có phân bố chuẩn tắc nhiều chiều
# Note: chổ này vẫn tương đương lấy MultivariateNormal(0, I)
# viết vầy cho tiện, đơn giản (hơi mẹo tí)
epsilon = torch.randn_like(x0, device=x0.device)
xt = model.sample_q(x0, t, epsilon=epsilon)
epsilon_theta = model.epsilon_model(xt, t)
# [Pseudocode T7] 7.1 chổ này là tính loss
return F.mse_loss(epsilon, epsilon_theta)
def train_denoise_diffusion_probabilistic_model(
dataset, test_size, batch_size, n_epochs, verbose=False):
"""Huấn luyện mô hình
:param dataset: tập dữ liệu X gồm D cột và n hàng
:param test_size: tỉ lệ validation
:param batch_size: batch_size huấn luyện
:param n_epochs: số bước tối ưu
:param verbose: có in ra dài dòng lê thê kooooo
"""
x_train, x_val = train_test_split(dataset, test_size=test_size)
train_dataset = DataLoader(x_train, batch_size=batch_size, shuffle=True)
validation_dataset = DataLoader(x_val, batch_size=batch_size, shuffle=True)
# Tùy chỉnh model, bạn có thể tăng, giảm độ phức tạp n_couple_layers tùy muốn
model = DenoisingDiffusionProbabilisticModel(
EpsilonThetaNetwork(n_steps=n_steps, device=device, dtype=dtype),
n_steps=n_steps, device=device)
# Thiết lập thuật toán tối ưu
optimizer = torch.optim.RMSprop(model.epsilon_model.parameters())
loss_train = []
loss_validation = []
for epoch in tqdm.tqdm(range(n_epochs)):
train_loss = []
validation_loss = []
# [Pseudocode T3] x0 ~ q(x0) lấy mẫu huấn luyện
for step, x_batch_train in enumerate(train_dataset):
model = model.train()
if model.training:
optimizer.zero_grad()
loss_value = loss_func(x_batch_train, model)
# [Pseudocode T7] 7.2 chổ này là cập nhật vector gradient
loss_value.backward()
optimizer.step()
train_loss.append(loss_value.item())
for step, x_batch_validation in enumerate(validation_dataset):
model = model.eval()
with torch.no_grad():
loss_value = loss_func(x_batch_train, model)
validation_loss.append(loss_value.item())
train_mse = np.mean(train_loss) # hơi lười =))
validation_mse = np.mean(validation_loss) # hơi lười =))
loss_train.append(train_mse)
loss_validation.append(validation_mse)
if verbose:
tqdm.tqdm.write(
f"[{str(epoch).zfill(4)}] " +
f"train loss {'{:.6f}'.format(train_nll_per_sample)} " +
f"val loss {'{:.6f}'.format(validation_nll_per_sample)}")
return model, loss_train, loss_validation
dict_model = {}
for i in range(len(datasets)):
name = names_dataset[i]
dataset = datasets[name]
model, loss_train, loss_validation = train_denoise_diffusion_probabilistic_model(
dataset, test_size=0.25, batch_size=1024, n_epochs=n_epochs, verbose=False)
dict_model[name] = model, loss_train, loss_validationdef visualize_for_dataset(name, axes, idx_axes, model, loss_train, loss_validation):
"""Trực quan hóa dành cho ax tương ứng
"""
x_dataset = datasets[name]
# Tính toán chổ này padding cho đẹp :D
min_x0 = np.percentile(x_dataset[:, 0], 2.5)
min_x1 = np.percentile(x_dataset[:, 1], 2.5)
max_x0 = np.percentile(x_dataset[:, 0], 97.5)
max_x1 = np.percentile(x_dataset[:, 1], 97.5)
padding_x0 = (max_x0 - min_x0) / 10
padding_x1 = (max_x1 - min_x1) / 10
min_x0 = min_x0 - padding_x0
max_x0 = max_x0 + padding_x0
min_x1 = min_x1 - padding_x1
max_x1 = max_x1 + padding_x1
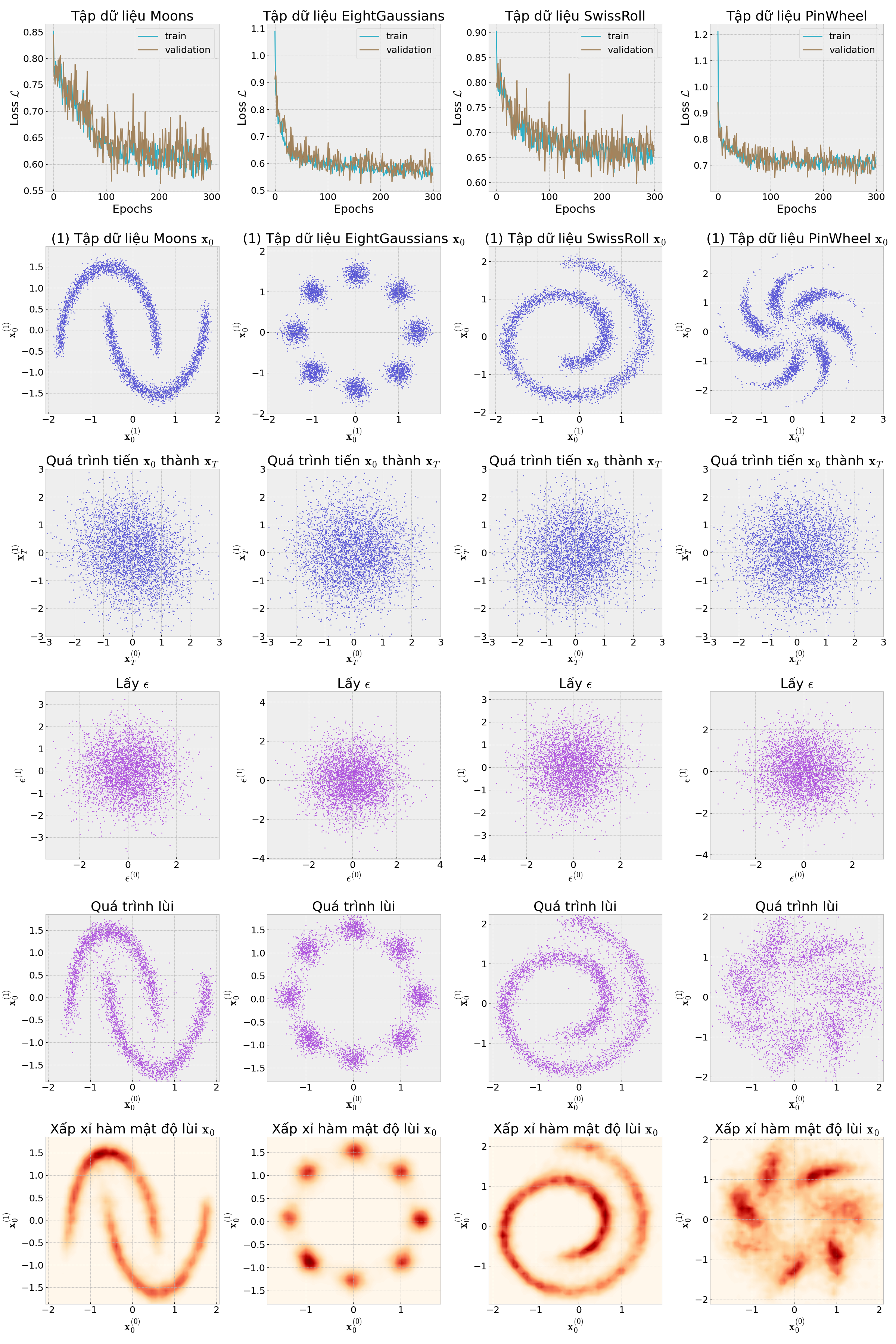
axes[0, idx_axes].plot(loss_train, color="#30b0c7")
axes[0, idx_axes].plot(loss_validation, color="#a2845e")
axes[0, idx_axes].set(
title=f"Tập dữ liệu {name}",
xlabel="Epochs", ylabel="Loss $\mathcal{L}$")
axes[0, idx_axes].legend(["train", "validation"], loc="upper right")
# Biến đỗi x_0 -> x_t từ tập dữ liệu
xt = model.forward_process(x_dataset)
axes[1, idx_axes].scatter(x_dataset[:, 0], x_dataset[:, 1], color="#5856d6", s=2)
axes[1, idx_axes].set(
title="(1) Tập dữ liệu " + name + " $\mathbf{x}_0$",
xlabel="$\mathbf{x}_0^{(1)}$", ylabel="$\mathbf{x}_0^{(1)}$")
axes[2, idx_axes].scatter(xt[:, 0], xt[:, 1], color="#5856d6", s=2)
axes[2, idx_axes].set(
title="Quá trình tiến $\mathbf{x}_0$ thành $\mathbf{x}_T$",
xlabel="$\mathbf{x}_T^{(0)}$", ylabel="$\mathbf{x}_T^{(1)}$")
axes[2, idx_axes].set_xlim([-3, 3])
axes[2, idx_axes].set_ylim([-3, 3])
# Lấy mẫu epsilon từ N(0, I)
eps = np.random.normal(size=(len(x_dataset), 2))
# Biến đổi từ epsilon -> x0
x_samples = model.reverse_process(len(x_dataset))
x_samples = x_samples.detach().numpy()
axes[3, idx_axes].scatter(eps[:, 0], eps[:, 1], color="#af52de", s=2)
axes[3, idx_axes].set(
title="Lấy $\epsilon$",
xlabel="$\epsilon^{(0)}$", ylabel="$\epsilon^{(1)}$")
axes[4, idx_axes].scatter(x_samples[:, 0], x_samples[:, 1], color="#af52de", s=2)
axes[4, idx_axes].set(
title="Quá trình lùi",
xlabel="$\mathbf{x}_0^{(0)}$", ylabel="$\mathbf{x}_0^{(1)}$")
axes[4, idx_axes].set_xlim([min_x0, max_x0])
axes[4, idx_axes].set_ylim([min_x1, max_x1])
# Vẽ countour map
n_point = 50 # số điểm neo
x0_lin = np.linspace(min_x0, max_x0, n_point)
x1_lin = np.linspace(min_x1, max_x1, n_point)
x0_grid, x1_grid = np.meshgrid(x0_lin, x1_lin)
x_contour = np.hstack([x0_grid.reshape(n_point ** 2, 1),
x1_grid.reshape(n_point ** 2, 1)])
z_contour = np.exp(model.pdf_reverse_samples(x_contour).reshape(n_point, n_point))
axes[5, idx_axes].contourf(x0_grid, x1_grid, z_contour, cmap="OrRd", levels=100)
axes[5, idx_axes].set_xlim([min_x0, max_x0])
axes[5, idx_axes].set_ylim([min_x1, max_x1])
axes[5, idx_axes].set(
title="Xấp xỉ hàm mật độ lùi $\mathbf{x}_0$",
xlabel="$\mathbf{x}_0^{(0)}$", ylabel="$\mathbf{x}_0^{(1)}$")
fig, axes = plt.subplots(6, len(names_dataset), figsize=(6 * len(names_dataset), 6 * 6),
gridspec_kw={'width_ratios': [1] * len(names_dataset)})
for i in range(len(datasets)):
name = names_dataset[i]
model, loss_train, loss_validation = dict_model[name]
visualize_for_dataset(name, axes, i, model, loss_train, loss_validation)
plt.tight_layout()
plt.show()
4. Ứng dụng:
Phần lớn nhóm mô hình thuộc họ DDPM dùng phục vụ cho các bài toán ảnh tạo sinh. Stable Diffusion là một trong những mô hình thành công khi xây dựng Diffusion Process kết hợp với kiến trúc mạng UNet.
Một số bài hướng dẫn trên mạng cho tập dữ liệu ảnh, bạn đọc quan tâm có thể tìm hiểu qua đường dẫn sau:

Ảnh từ Keras - Denoising Diffusion Probabilistic Model
Phần giải thích trong bài viết của ThetaLog vẫn chưa đề cập đến kỹ thuật Conditional Diffusion Models, trong nhiều bài toán bạn sẽ muốn kiểm soát được ngữ cảnh lấy mẫu, việc sinh ra mẫu từ một mô tả ngữ cảnh nếu bạn đọc quan tâm có thể tìm hiểu thêm (ứng dụng trong bài toán tạo sinh từ mô tả văn bản).
Jupyter notebook bài viết bạn đọc có thể truy cập ở: https://github.com/quangtiencs/theta-notebook/
Tham khảo
- Jonathan Ho, Ajay Jain, Pieter Abbeel. Denoising Diffusion Probabilistic Models. https://arxiv.org/abs/2006.11239
- Ilya Katsov. The Theory and Practice of Enterprise AI (2nd). https://www.enterprise-ai-book.com/
- Kevin P. Murphy. Probabilistic Machine Learning: Advanced Topics. https://probml.github.io/pml-book/book2.html
- ELBO https://en.wikipedia.org/wiki/Evidence_lower_bound
- labml.ai Deep Learning Paper Implementations. https://github.com/labmlai/annotated_deep_learning_paper_implementations
- Diederik P Kingma, Max Welling - Auto-Encoding Variational Bayes. https://arxiv.org/abs/1312.6114